


Data engineering has become one of the fastest-growing careers in the technology industry. As companies generate massive amounts of data every day, the demand for skilled data engineers is increasing rapidly across the world. From Netflix and Amazon to banking systems, healthcare platforms, and AI companies, almost every organization depends on data pipelines, cloud systems, and real-time analytics. This is why data engineering is becoming one of the highest-paying and most future-proof careers in 2026. If you are planning to start your journey in data engineering but feel confused about what to learn, this roadmap will help you understand the skills, tools, and projects required to become a successful data engineer. What Does a Data Engineer Do? A data engineer builds systems that collect, process, store, and transform data efficiently. Data engineers are responsible for creating data pipelines that move data from multiple sources into databases, cloud platforms, and analytics systems. Their work helps data analysts, data scientists, and business teams access clean and reliable data. Modern data engineers also work with big data technologies, cloud platforms, streaming systems, and real-time processing tools. Why Data Engineering Is a High-Demand Career In 2026, businesses are handling larger amounts of data than ever before. Companies need professionals who can build scalable systems capable of processing millions of records efficiently. The rise of AI, machine learning, cloud computing, and real-time analytics has increased the demand for data engineers globally. Many companies now prioritize hiring data engineers because data-driven decision-making has become essential for business growth. Data engineering also offers: Step 1: Learn SQL Properly SQL is one of the most important skills for every data engineer. Most company data is stored inside relational databases, and SQL is used to query, transform, and manage that data. A beginner should focus on learning: Strong SQL knowledge is mandatory before moving to advanced big data tools. Step 2: Learn Python for Data Engineering Python is widely used in data engineering because it is simple, powerful, and supports automation. Data engineers use Python for: Popular Python libraries include Pandas, PySpark, Requests, and SQLAlchemy. A beginner should practice writing clean and efficient Python code regularly. Step 3: Understand Databases A data engineer must understand how databases work. You should learn both: Relational Databases Examples include: These databases store structured data. NoSQL Databases Examples include: These databases handle large-scale and flexible data systems. Understanding indexing, partitioning, and database optimization is very important. Step 4: Learn ETL and Data Pipelines ETL stands for Extract, Transform, and Load. This is the core process used in data engineering. Data engineers extract data from multiple systems, transform it into usable formats, and load it into warehouses or analytics platforms. You should understand: ETL pipelines are used in almost every data engineering project. Step 5: Learn Big Data Technologies As data volume grows, companies use distributed systems to process large datasets efficiently. Apache Spark is one of the most important big data technologies in 2026. Spark is used for: You should also understand: Big data technologies are widely used in enterprise environments. Step 6: Learn Cloud Platforms Cloud computing has become a major part of modern data engineering. Most companies now use cloud platforms instead of traditional on-premise systems. The most popular cloud platforms are: A beginner should focus on learning cloud storage, data warehouses, and data processing services. Important tools include: Cloud skills are highly valuable in the job market. Step 7: Learn Real-Time Data Processing Modern applications process streaming data continuously. Companies like Uber, Netflix, Swiggy, and Amazon depend heavily on real-time data systems. This is why learning streaming technologies is becoming important for modern data engineers. Key technologies include: These tools help process live events with low latency. Step 8: Learn Data Warehousing Concepts Data warehouses store processed business data for reporting and analytics. A data engineer should understand: Popular cloud warehouses include Snowflake, Redshift, and BigQuery. Step 9: Build Real Projects Projects are one of the most important parts of learning data engineering. Companies want practical experience, not only theoretical knowledge. Beginners should build projects such as: Projects help improve practical understanding and strengthen resumes. Step 10: Learn Workflow Orchestration Tools Large data pipelines need automation and scheduling systems. Apache Airflow is one of the most widely used orchestration tools. Airflow helps schedule, monitor, and manage workflows efficiently. Data engineers use orchestration tools to automate production pipelines. Important Tools Every Data Engineer Should Know In 2026, these tools are highly valuable: You do not need to master everything at once. Start step by step. Common Mistakes Beginners Make Many beginners try to learn too many tools together without understanding the basics. Some focus only on watching tutorials without building projects. Others skip SQL and directly jump into cloud platforms or Spark. A better approach is: Data engineering takes time, but regular practice brings strong results. Future of Data Engineering The future of data engineering looks extremely strong. As AI systems continue to grow, companies will require even larger data infrastructure and real-time processing systems. Technologies like cloud computing, streaming analytics, and AI-powered pipelines will continue creating new opportunities for skilled data engineers. This makes data engineering one of the safest and most promising careers for the future. Data engineering is not only about learning tools. It is about understanding how modern data systems work and solving real business problems using scalable technologies. If you follow a structured roadmap, practice consistently, and build real projects, you can become a successful data engineer in 2026. Start with SQL and Python, gradually move toward cloud and big data technologies, and focus on hands-on learning instead of only theory. The demand for skilled data engineers is growing rapidly, and this is one of the best times to start your journey in the data engineering field.

How Swiggy, Zomato, and Uber Use Live Data Processing
Every time you book a cab on Uber or order food using Swiggy or Zomato, thousands of data events are processed instantly behind the scenes. What looks simple on the mobile app is actually powered by massive real-time data systems working continuously every second. Modern companies cannot wait hours to process information. Customers expect live tracking, instant updates, accurate ETAs, and fast recommendations. This is why companies today depend heavily on live data processing technologies. In this article, we will understand how platforms like Swiggy, Zomato, and Uber use real-time data processing to handle millions of users efficiently. What Is Live Data Processing? Live data processing means handling data immediately after it is generated. Instead of storing data first and processing it later, modern systems analyze events instantly. This helps businesses respond quickly and provide real-time experiences to users. For example, when a customer books a ride on Uber, the platform instantly identifies nearby drivers, calculates estimated arrival time, checks traffic conditions, and sends notifications. All these actions happen within seconds using streaming data systems. Similarly, Swiggy and Zomato continuously process order updates, delivery partner locations, restaurant availability, and payment information in real time. How Uber Uses Real-Time Data Uber is one of the best examples of large-scale real-time data engineering. When a rider opens the Uber app, live GPS data from thousands of drivers is already being processed continuously. Once the user requests a ride, Uber’s systems immediately search for nearby drivers, calculate distances, estimate ride fares, and assign the best driver. During the ride, the system keeps tracking both the driver and rider locations continuously. Traffic updates, route optimization, and ETA calculations are refreshed every few seconds. Uber also uses real-time analytics for surge pricing. When demand increases in a particular area, the system instantly detects the spike and adjusts prices automatically. Without live data processing, Uber would not be able to provide accurate ride tracking and quick driver matching. How Swiggy Handles Streaming Data Swiggy depends heavily on real-time systems to manage food delivery operations smoothly. When a customer places an order, the information is immediately sent to the restaurant. At the same time, Swiggy’s system searches for nearby delivery partners and assigns the order based on factors like distance, traffic, and delivery time. As the order moves through different stages, customers receive live updates such as: All these updates are powered by streaming data pipelines. Swiggy also analyzes live customer activity during peak hours to improve delivery efficiency and reduce delays. How Zomato Uses Live Data Zomato processes millions of customer interactions every day. Every search, restaurant click, order placement, and payment generates data events. The platform uses live data processing to provide better customer experiences. When users search for restaurants, Zomato instantly shows personalized recommendations based on location, preferences, ratings, and previous activity. Real-time systems also help Zomato estimate delivery times accurately. If traffic conditions change or delivery partners become unavailable, the system recalculates ETAs immediately. Zomato additionally uses live analytics to monitor customer behavior, track active orders, and identify operational issues before they become serious problems. Technologies Behind These Systems Companies like Uber, Swiggy, and Zomato use modern big data technologies to process continuous streams of information. Apache Kafka is commonly used for handling millions of real-time events efficiently. Streaming platforms like Apache Spark Streaming and Apache Flink process incoming data with very low latency. Cloud platforms such as AWS, Azure, and Google Cloud provide scalable infrastructure to support massive workloads. Databases like Cassandra and Redis help store and retrieve live operational data quickly. Together, these technologies allow companies to process huge amounts of data without delays. Why Real-Time Processing Is Important Modern users expect everything instantly. A delay of even a few seconds can affect customer satisfaction. Real-time data systems help companies: These systems also help businesses make faster decisions using live analytics instead of relying only on historical reports. Challenges in Live Data Systems Handling real-time data at large scale is not easy. Companies process billions of events every day from mobile apps, GPS devices, payment systems, and cloud services. Maintaining low latency while handling massive traffic requires strong infrastructure and advanced engineering. Data engineers must ensure systems remain reliable even during heavy traffic periods such as weekends, holidays, or large events. Scalability, fault tolerance, monitoring, and data consistency are major challenges in modern streaming architectures. Role of Data Engineers Data engineers play a critical role in building and maintaining these systems. They design streaming pipelines, manage cloud infrastructure, optimize processing jobs, and ensure data flows smoothly across platforms. Modern data engineers work with technologies like Apache Kafka, Spark, Databricks, AWS, Azure, and real-time analytics tools to build scalable systems capable of handling millions of users. As more companies adopt streaming architectures, demand for skilled data engineers continues to grow rapidly. Platforms like Swiggy, Zomato, and Uber rely completely on live data processing to deliver fast and seamless customer experiences. From ride tracking to food delivery updates, everything depends on real-time systems working continuously behind the scenes. Modern businesses no longer process data only for reports and dashboards. Today, data is used instantly to make decisions, improve customer experiences, and optimize operations in real time. Learning real-time data technologies is becoming one of the most important skills for aspiring data engineers in 2026.
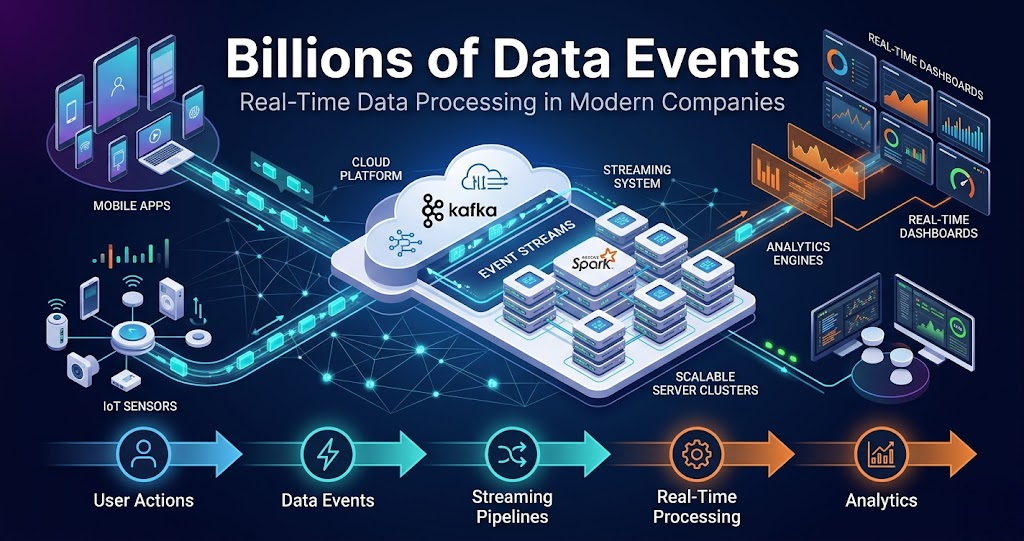
How Companies Handle Billions of Data Events Every Day
Modern applications generate billions of data events every day from user activity, mobile apps, cloud systems, and streaming platforms. Platforms like Netflix, Amazon, Uber, YouTube, and Instagram process billions of data events daily to provide smooth user experiences and intelligent recommendations. Whenever you: a data event is created behind the scenes. Managing billions of these events efficiently is one of the biggest challenges in modern data engineering. In this blog, you will understand how companies process huge-scale data events using real-time pipelines, distributed systems, and cloud technologies. What Are Data Events? A data event is any user or system activity generated inside an application. Examples include: Every action creates valuable information that companies use for analytics, recommendations, monitoring, and business decisions. Why Companies Process Data Events in Real Time Modern businesses cannot wait several hours to analyze user activity. Real-time systems help companies: For example: This is why real-time event processing has become critical in modern applications. How Data Events Move Through Systems A modern data pipeline usually works like this: User Activity → Event Streaming → Processing Engine → Storage → Analytics Dashboard Whenever a user interacts with an application: This entire process often happens within seconds. Technologies Used for Event Processing Modern companies use distributed technologies to handle billions of events efficiently. Popular technologies include: These tools help organizations build scalable and fault-tolerant data pipelines. Role of Apache Kafka Apache Kafka is one of the most widely used event streaming platforms. Kafka helps companies: For example: Kafka acts like a central highway for moving real-time data across applications. Role of Apache Spark Apache Spark helps process huge-scale data quickly. Spark can: Many companies combine Kafka and Spark together for real-time analytics systems. Spark is highly popular because it processes massive datasets much faster than traditional systems. Importance of Cloud Platforms Cloud platforms make large-scale event processing easier and more scalable. Cloud providers like: offer services that help companies: Modern data engineering heavily depends on cloud computing because data volume keeps growing rapidly. Challenges in Processing Billions of Events Handling huge-scale data systems is not easy. Companies face challenges like: To solve these problems, businesses use distributed architectures and monitoring systems. Data engineers play an important role in building stable and scalable pipelines. Why This Matters for Data Engineers Modern data engineering jobs are heavily focused on: Companies are actively looking for engineers who understand: As businesses generate more data every year, demand for these skills continues growing rapidly. Modern companies process billions of data events every day to deliver fast, intelligent, and personalized digital experiences. From streaming platforms and ride-sharing apps to e-commerce systems and banking applications, real-time event processing powers modern technology infrastructure. Technologies like Kafka, Spark, cloud computing, and distributed pipelines are becoming essential in the world of data engineering. This is why learning modern big data and real-time processing technologies can create strong career opportunities in 2026 and beyond.
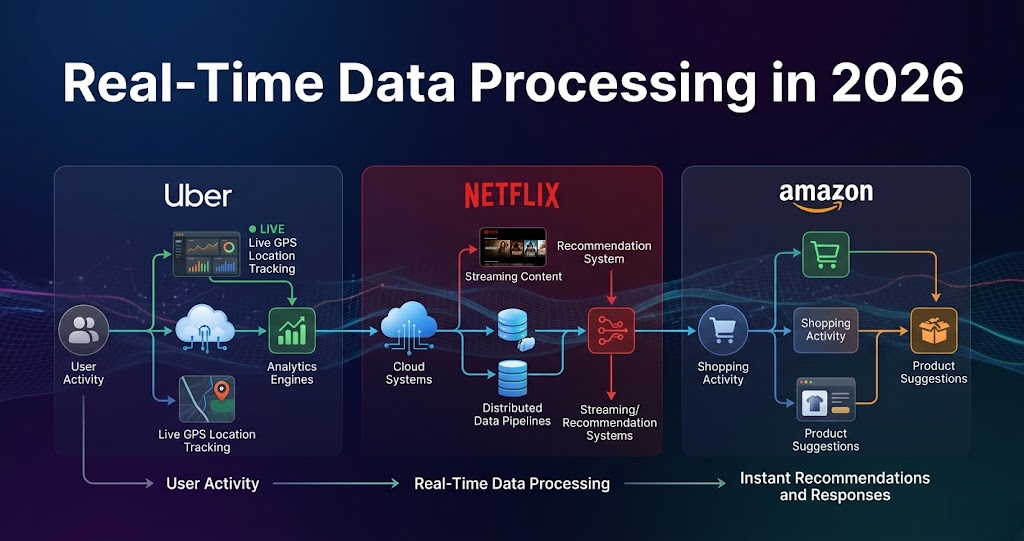
How Uber, Netflix, and Amazon Process Real-Time Data
Every second, companies like Uber, Netflix, and Amazon process massive amounts of data from millions of users across the world. Whether you are booking a ride, watching a movie, or ordering a product, these platforms are continuously collecting and processing real-time information. The reason everything feels fast and smooth is because these companies use advanced data engineering systems behind the scenes. Modern businesses cannot wait hours to process information anymore. They need real-time data processing to make instant decisions, improve customer experience, and keep systems running efficiently. In this blog, you will understand how companies like Uber, Netflix, and Amazon process real-time data using modern big data technologies. What is Real-Time Data Processing? Real-time data processing means handling data immediately as it is generated. Instead of storing data and processing it later in batches, companies process events instantly. This helps businesses respond quickly to user actions and system changes. Examples of real-time data include: Modern applications depend heavily on real-time systems because users expect instant responses. How Uber Processes Real-Time Data Uber handles millions of ride requests every day. When a user books a ride, the system must process location data, driver availability, traffic conditions, and pricing instantly. Uber continuously processes: This data flows through streaming pipelines and distributed systems in real time. If Uber used slow batch systems, ride matching and pricing would become delayed, creating poor user experience. Real-time processing helps Uber: How Netflix Uses Real-Time Data Netflix processes huge amounts of streaming and user activity data every second. Whenever you: Netflix collects and analyzes this information instantly. This helps Netflix: Netflix uses modern distributed systems and big data processing tools to handle this scale efficiently. Its recommendation engine depends heavily on real-time analytics and machine learning systems. How Amazon Uses Real-Time Data Amazon processes real-time data to improve shopping experience and manage operations. When you search or buy products, Amazon instantly analyzes: This helps Amazon provide: Real-time systems also help Amazon detect fraud and monitor transactions immediately. Technologies Used Behind the Scenes Companies like Uber, Netflix, and Amazon use modern data engineering technologies to process large-scale real-time data. Some commonly used technologies include: These tools help process millions of events quickly and reliably. Role of Data Pipelines Data pipelines are one of the most important parts of real-time systems. A pipeline continuously moves data from applications into processing systems and analytics platforms. A simple flow looks like this: User Activity → Streaming Pipeline → Real-Time Processing → Analytics → Instant Response These pipelines help companies process and react to data immediately. Without strong pipelines, real-time systems cannot work efficiently. Why Real-Time Data is Important Modern users expect fast responses from applications. People expect: Real-time processing helps companies improve customer experience and business performance. It also helps businesses: This is why real-time data processing is becoming essential in modern technology systems. What Beginners Can Learn from This Understanding how real-time systems work helps beginners understand the importance of modern data engineering. Today’s data engineers work with: Skills like Apache Spark, Kafka, cloud computing, and data pipelines are becoming highly valuable in 2026. Learning these technologies can open strong career opportunities in modern data companies. Companies like Uber, Netflix, and Amazon depend heavily on real-time data processing to deliver fast and personalized experiences. From ride matching and movie recommendations to shopping systems and analytics, modern applications rely on advanced data engineering infrastructure. As businesses continue growing digitally, the importance of real-time data systems will continue increasing. This is why technologies related to streaming, cloud computing, and big data processing are becoming some of the most important skills in modern data engineering careers.

What Happens Behind the Scenes When You Use Netflix or Amazon?
Every day, millions of people use platforms like Netflix and Amazon without thinking about what happens behind the scenes. When you watch a movie on Netflix or order a product on Amazon, everything feels fast and smooth. But in reality, there is a massive data system working continuously in the background. These companies process huge amounts of data every second. They use modern technologies, cloud platforms, data pipelines, and big data systems to deliver personalized recommendations, fast search results, smooth streaming, and reliable user experiences. In this blog, you will understand how companies like Netflix and Amazon use modern data engineering systems behind the scenes. How Data is Generated Whenever you use Netflix or Amazon, your activity creates data. For example: Millions of users generate billions of events daily. This creates massive amounts of real-time data. Companies collect this information continuously to improve customer experience and business performance. Data Collection Process The first step is collecting user activity data. When a user clicks, searches, watches, or purchases something, the application sends event data to backend systems. This data is collected from: These events are sent into large-scale data pipelines. Role of Data Pipelines Data pipelines move data from applications into storage and processing systems. A typical flow looks like this: User Activity → Event Collection → Data Pipeline → Processing → Analytics These pipelines help companies: Without data pipelines, companies cannot handle such large-scale systems efficiently. How Netflix Recommends Movies Netflix uses data engineering and machine learning together. When you watch movies, Netflix tracks: This data is processed using large-scale systems and recommendation algorithms. Based on your activity, Netflix predicts what you may like next and shows personalized recommendations. This entire process happens automatically using modern data infrastructure. How Amazon Handles Recommendations Amazon works similarly. When you search or buy products, Amazon analyzes: Using this data, Amazon recommends products that you are more likely to buy. This improves user experience and increases sales. Technologies Used Behind the Scenes Companies like Netflix and Amazon use modern data engineering tools to handle massive scale. Some commonly used technologies include: These systems process millions of records quickly and reliably. Importance of Real-Time Processing Modern applications require real-time processing. For example: Real-time data processing helps companies make fast decisions and improve customer experience. This is why technologies like Apache Spark and streaming systems are becoming very important. Why Data Engineering is Critical Behind every modern application, data engineers build and maintain the systems that move and process data. Data engineers: Without data engineering, platforms like Netflix and Amazon cannot operate efficiently. What Beginners Can Learn from This Understanding how companies use data helps beginners understand the importance of data engineering. Modern companies depend heavily on: Learning these skills can open strong career opportunities in modern technology companies. When you use Netflix or Amazon, a huge data engineering system works behind the scenes to provide a smooth experience. From collecting user activity to processing massive amounts of data in real time, these companies depend heavily on modern data technologies. This is why data engineering, cloud computing, and big data skills are becoming more important every year. As businesses continue growing digitally, the demand for professionals who can build and manage these systems will continue to increase in 2026 and beyond.

Why Companies Are Moving from Hadoop to Spark in 2026
For many years, Hadoop was one of the most popular technologies in big data processing. Companies used Hadoop to store and process huge amounts of data across distributed systems. It played a major role in the growth of data engineering and big data analytics. However, in 2026, many companies are slowly moving away from Hadoop and adopting Apache Spark instead. The reason is simple modern businesses need faster processing, better performance, and support for real-time data systems. In this blog, you will understand why companies are moving from Hadoop to Spark and why Spark has become one of the most important tools in modern data engineering. What is Hadoop? Hadoop is an open-source framework used for storing and processing large datasets. It uses distributed storage and distributed processing to handle big data across multiple systems. Hadoop mainly works using: For many years, Hadoop was the standard solution for big data systems. What is Apache Spark? Apache Spark is also a distributed data processing framework, but it is designed to process data much faster than Hadoop MapReduce. Spark processes data in memory, which makes it significantly faster. It also supports: Because of this flexibility and speed, Spark has become highly popular in modern data engineering. Why Companies Are Moving from Hadoop to Spark One of the biggest reasons companies are moving to Spark is performance. Hadoop MapReduce processes data by reading and writing to disk multiple times, which makes it slower. Spark uses in-memory processing, reducing processing time significantly. This helps companies handle large datasets much faster. Another major reason is real-time processing. Modern businesses need real-time analytics and faster decision-making. Hadoop is mainly designed for batch processing, while Spark supports both batch and real-time data processing. Spark is also easier to use for developers. It supports multiple languages like Python, Scala, and SQL, making development faster and more flexible. Companies also prefer Spark because it integrates well with modern cloud platforms like AWS, Azure, and GCP. As businesses move to cloud-based systems, Spark fits naturally into modern architectures. Hadoop vs Spark: Key Differences Hadoop and Spark both process big data, but they work differently. Hadoop: Spark: Because of these advantages, Spark is becoming the preferred choice for modern data systems. Real-World Use Cases Many companies now use Spark for: Industries like e-commerce, finance, healthcare, and streaming platforms rely heavily on Spark because they need fast and scalable processing. Is Hadoop Still Used? Even though Spark is growing rapidly, Hadoop is not completely gone. Some companies still use Hadoop storage systems like HDFS. In many cases, Spark actually runs on top of Hadoop infrastructure. So Hadoop still exists in some environments, but Spark is becoming the main processing engine. Why Learning Spark is Important in 2026 For anyone planning a career in data engineering, Spark has become a must-have skill. Many job descriptions now require Spark knowledge because companies are actively using it in production systems. Learning Spark helps you: As more companies move to modern cloud and real-time architectures, Spark skills are becoming more valuable. Common Mistakes Beginners Make Many beginners focus only on Hadoop because it was popular in the past. However, modern data engineering is moving toward Spark-based systems. Another mistake is trying to learn advanced Spark concepts before understanding basics like SQL and data pipelines. Building strong fundamentals first makes learning easier. Companies are moving from Hadoop to Spark because modern data systems require faster processing, real-time capabilities, and better scalability. While Hadoop played an important role in big data history, Spark is becoming the preferred choice for modern data engineering in 2026. Its speed, flexibility, and cloud compatibility make it ideal for today’s business needs. If you want to build a strong career in data engineering, learning Apache Spark is one of the smartest decisions you can make today.

Top Data Engineering Tools You Must Learn in 2026 (Beginner to Advanced)
Data engineering is one of the fastest-growing fields in technology. Companies today depend on data to make decisions, build products, and improve performance. Because of this, data engineers play a key role in building systems that collect, process, and store data. If you want to become a data engineer in 2026, learning the right tools is very important. There are many tools available, but you do not need to learn everything. You just need to focus on the most important tools used in real-world projects. In this blog, you will understand the top data engineering tools you must learn, from beginner level to advanced level. Why Learning Data Engineering Tools is Important Data engineering is not only about theory. It is about building real systems that work with large amounts of data. Tools help you: Without tools, it is difficult to work in real projects. That is why learning tools step by step is important. Beginner-Level Tools If you are starting from scratch, you should first focus on basic tools. These will help you understand core concepts. SQL SQL is the most important skill for data engineers. It is used to query and manage data in databases. You will use SQL in almost every project. Without SQL, it is very difficult to move forward in data engineering. Python Python is widely used for data processing and automation. It is simple to learn and very powerful. You can use Python for: Basic Databases Understanding how databases work is important. You should learn: These tools help you build a strong foundation. Intermediate-Level Tools Once you understand the basics, you can move to intermediate tools that are used in real data pipelines. Apache Spark Apache Spark is used for processing large amounts of data quickly. It supports distributed computing and is widely used in companies. It helps in: Data Warehouses Data warehouses are used to store processed data for analysis. Popular tools include: These tools are important for analytics and reporting. ETL Tools ETL tools help move and transform data from one system to another. Examples: These tools help automate data pipelines. Advanced-Level Tools At the advanced level, you will work with modern data architecture tools. DBT (Data Build Tool) DBT is used for transforming data inside data warehouses. It allows you to write SQL-based transformations. It is widely used in modern data engineering workflows. Streaming Tools Streaming tools are used for real-time data processing. Examples: These tools are used in applications like real-time analytics and monitoring systems. Cloud Platforms Cloud platforms are essential for data engineering in 2026. You should learn: These platforms provide storage, processing, and data services. How to Learn These Tools (Right Approach) Many beginners make the mistake of trying to learn everything at once. This creates confusion. Instead, follow this step-by-step approach: Practice is very important. Try to build small projects to understand how tools work together. Common Mistakes to Avoid While learning data engineering tools, avoid these mistakes: Focus on understanding how tools are used in real projects. Data engineering tools are the backbone of modern data systems. In 2026, companies are using a combination of tools to build scalable and efficient data pipelines. You do not need to learn everything at once. Start with basics, move step by step, and focus on real-world use cases. By learning the right tools in the right order, you can build a strong career in data engineering.

Apache Spark for Beginners: Why It’s a Must-Have Skill in 2026
In today’s data-driven world, companies are handling massive amounts of data every day. Processing this data quickly and efficiently has become a major challenge. This is where Apache Spark comes in. Apache Spark is one of the most popular tools used in data engineering for large-scale data processing. Many companies rely on Spark to build fast and scalable data pipelines. If you are planning to start a career in data engineering, learning Apache Spark in 2026 is not just useful, it is essential. What is Apache Spark? Apache Spark is an open-source data processing framework used to process large amounts of data quickly. It works in a distributed environment, which means it can process data across multiple machines at the same time. In simple terms, Spark allows you to handle big data efficiently without waiting for long processing times. Unlike traditional systems, Spark processes data in memory, making it much faster. It supports multiple programming languages like Python, Scala, and SQL, making it flexible for different users. Why Apache Spark is Important in Data Engineering Data engineering is all about building systems that handle large data. Spark plays a key role in this because it can process huge datasets quickly and reliably. Many modern data pipelines depend on Spark for transforming and analyzing data. Whether it is batch processing or real-time data, Spark can handle both. As companies continue to generate more data, the need for tools like Spark is increasing. Key Features of Apache Spark Apache Spark provides several features that make it powerful and widely used. These features make Spark a complete solution for data processing. How Apache Spark Works Apache Spark works by dividing data into smaller parts and processing them across multiple machines. This approach is called distributed processing. Instead of processing data in a single system, Spark distributes the workload. This reduces processing time and improves performance. It uses components like: This modular design makes Spark flexible for different use cases. Why Spark is a Must-Have Skill in 2026 There are several reasons why learning Apache Spark is important in 2026. First, it is widely used in the industry. Many companies use Spark as a core part of their data systems. Second, it offers strong career opportunities. Data engineers with Spark skills are in high demand. Third, it supports modern data architectures. Tools like Delta Lake, Snowflake, and cloud platforms work well with Spark. Fourth, it improves your ability to handle big data problems. This is a critical skill in today’s job market. Because of these reasons, Spark is considered a must-have skill for data engineers. How to Start Learning Apache Spark If you are a beginner, you can start learning Spark step by step. You do not need to learn everything at once. Start with: Once you understand the basics, you can move to advanced topics like optimization and real-time processing. Common Mistakes Beginners Make Many beginners make mistakes while learning Spark. Being aware of these can help you avoid problems. Learning step by step with practice is the best approach. Apache Spark is one of the most important tools in data engineering. It helps process large data efficiently and supports modern data systems. In 2026, companies are increasingly relying on Spark for building scalable and fast data pipelines. This makes it a valuable skill for anyone entering the data field. If you want to build a strong career in data engineering, learning Apache Spark is a smart and necessary step.
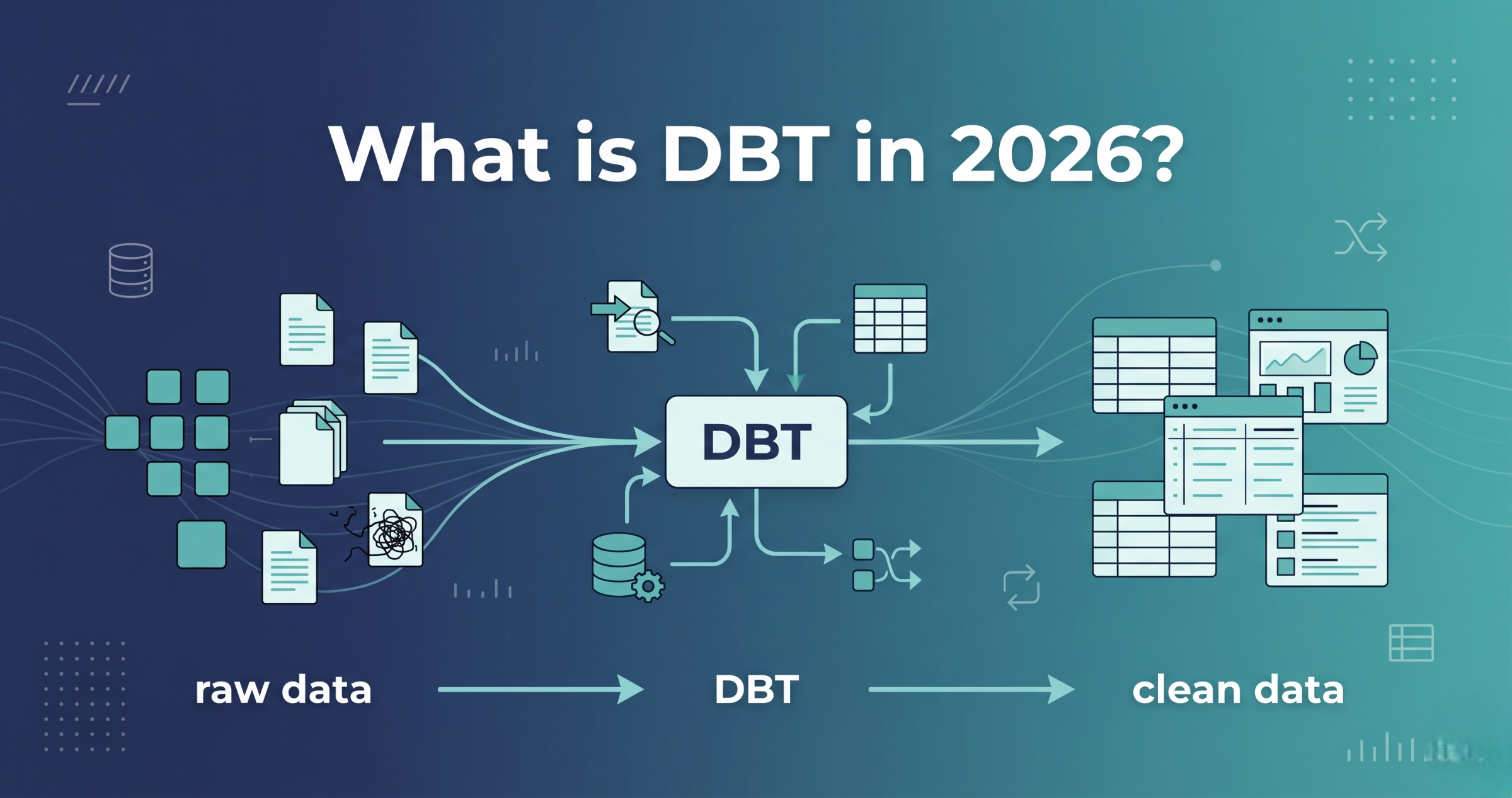
What is DBT and Why Data Engineers Are Using It in 2026?
In modern data engineering, managing and transforming data efficiently has become very important. Many companies are now dealing with large amounts of data, and traditional methods of handling data transformations are no longer enough. This is where DBT comes in. DBT, which stands for Data Build Tool, is becoming one of the most popular tools in data engineering in 2026. It helps data engineers transform raw data into clean, reliable, and analysis-ready data directly inside data warehouses. In this blog, you will understand what DBT is, how it works, and why more data engineers are using it. What is DBT? DBT is a tool used for transforming data inside a data warehouse. Instead of moving data to another system for processing, DBT works directly where the data is stored. In simple terms, DBT allows you to write SQL queries to transform raw data into useful tables that can be used for reporting and analysis. It focuses only on transformation, which is the “T” in ELT (Extract, Load, Transform). Data is first loaded into the warehouse, and then DBT is used to clean and organize it. This approach is faster and more efficient compared to older ETL methods. Why DBT is Important in Modern Data Engineering As companies move to cloud data platforms like Snowflake, BigQuery, and Redshift, the way data is processed has changed. Instead of processing data outside, transformations now happen inside the warehouse. DBT fits perfectly into this modern approach. It helps teams manage data transformations in a structured and organized way. Data engineers can build reusable models, track changes, and maintain data quality without creating complex pipelines. Because of this, DBT has become an essential tool in modern data workflows. Key Features of DBT DBT offers several features that make data engineering easier and more efficient. These features help teams build reliable and scalable data systems. How DBT Works in Data Pipelines In a typical modern data pipeline, data is first collected from different sources and loaded into a data warehouse. After that, DBT is used to transform the data. The process looks like this: Data is ingested into the warehouse → DBT transforms the data → Clean data is used for analytics and reporting DBT runs SQL models in a sequence, ensuring that each step depends on the previous one. This creates a clear and organized data flow. Why Data Engineers Are Using DBT in 2026 There are several reasons why DBT is widely used by data engineers today. First, it simplifies data transformation. Instead of writing complex code, engineers can use SQL, which is easier to learn and use. Second, it improves collaboration. Teams can work together using version control, making it easier to track changes and avoid errors. Third, it ensures data quality. With built-in testing, engineers can catch issues early before they affect reports. Fourth, it supports scalability. DBT works well with cloud data platforms, making it suitable for large-scale data systems. Because of these advantages, DBT has become a standard tool in many data teams. DBT vs Traditional ETL Traditional ETL tools process data outside the warehouse, which can be slower and more complex. They often require separate systems and additional maintenance. DBT follows the ELT approach, where data is loaded first and transformed later inside the warehouse. This reduces complexity and improves performance. Compared to traditional ETL, DBT is simpler, faster, and more efficient for modern data environments. When Should You Learn DBT? If you are planning to build a career in data engineering, learning DBT can be very helpful. It is especially useful if you are working with cloud data platforms or modern data stacks. You should consider learning DBT if you: Learning DBT can make you more valuable in the job market. DBT has become an important tool in modern data engineering. It simplifies data transformation, improves data quality, and helps teams build scalable data pipelines. As data continues to grow and cloud platforms become more popular, tools like DBT will play a key role in managing data efficiently. If you want to stay relevant in the data field in 2026, learning DBT is definitely a smart choice.

Top 5 High-Paying Data Careers in 2026 (And How to Start Each One)
With the rapid growth of technology, data has become one of the most valuable assets for companies. Because of this, careers related to data are growing very fast. Many people are now looking for high-paying data careers that offer strong growth and long-term stability. In 2026, data-related roles are not only in demand but also among the highest-paying jobs in the tech industry. However, many beginners feel confused about which career to choose and how to start. In this blog, you will understand the top 5 high-paying data careers in 2026 and a simple path to start each one. 1. Data Engineer Data engineering is one of the most in-demand and high-paying careers today. Data engineers build systems that collect, process, and store data so that it can be used for analysis and decision-making. This role is important because companies depend on clean and reliable data. Without data engineers, analytics and machine learning cannot work properly. To start a career in data engineering, focus on: Data engineering offers strong salary growth and long-term career stability. 2. Data Scientist Data scientists work on analyzing data and building models to make predictions. They help companies understand patterns and make better decisions. This role requires a combination of programming, statistics, and problem-solving skills. It is considered one of the most popular data careers. To start as a data scientist: Data scientists are highly paid because they directly impact business decisions. 3. Data Analyst Data analysts focus on understanding data and creating reports. They help businesses track performance and make decisions based on data. This is one of the best roles for beginners because it requires fewer technical skills compared to other data roles. To start as a data analyst: Data analyst roles are widely available and provide a good entry point into the data field. 4. Cloud Data Engineer Cloud data engineers work with cloud platforms like AWS, Azure, or GCP to build data systems. As more companies move to the cloud, this role is growing rapidly. This role combines data engineering with cloud skills, making it highly valuable. To start in this field: Cloud data engineers are in high demand and offer excellent salary packages. 5. Machine Learning Engineer Machine learning engineers build systems that use data to make predictions automatically. They work closely with data scientists but focus more on production systems. This role is more advanced and requires strong programming skills. To start as a machine learning engineer: This is one of the highest-paying roles in the data field. How to Choose the Right Career Choosing the right career depends on your interest and background. If you like building systems, data engineering is a good choice. If you enjoy analysis, data analyst or data scientist roles may be better. If you are interested in cloud technologies, cloud data engineering is a strong option. For those who like advanced problem-solving, machine learning is a good path. The most important thing is to start with basics and then move step by step. Data careers are among the highest-paying and fastest-growing options in 2026. Roles like data engineer, data scientist, and cloud data engineer offer excellent opportunities for beginners as well as experienced professionals. While each role has its own skills and learning path, all of them require consistency and practice. You do not need to learn everything at once. Start small, focus on one path, and build your skills gradually. With the right approach, you can build a successful career in the data field and take advantage of the growing demand in this industry.
