

Modern applications like Airbnb handle massive amounts of user data every day. Millions of people search for hotels, apartments, vacation homes, and travel experiences across different locations worldwide. To provide better user experiences, Airbnb uses advanced data engineering systems that process and analyze user activity continuously. In this article, we will understand how Airbnb uses data engineering for personalized recommendations and why data engineering plays a major role in modern recommendation systems. Why Personalized Recommendations Are Important When users open Airbnb, they expect to see relevant property suggestions based on their interests, budget, search history, and travel preferences. Without personalization, users would spend more time searching manually. Recommendation systems help improve: This is where large-scale data engineering becomes extremely important. How Airbnb Collects User Data Every action performed on Airbnb generates data events. For example: These events are collected continuously from websites and mobile applications. The data is then processed using modern data engineering pipelines. Real-Time Data Processing at Airbnb Airbnb uses real-time data processing systems to analyze user activity instantly. Streaming platforms and cloud-based pipelines help process millions of events every second. When a user searches for a property in a particular city, recommendation systems immediately analyze: This helps Airbnb display highly relevant recommendations quickly. Technologies Used in Airbnb Data Engineering Large-scale platforms like Airbnb use modern cloud and big data technologies such as: These tools help process huge datasets efficiently and support personalized recommendation engines. Cloud platforms also help scale infrastructure dynamically based on traffic demand. Role of Machine Learning in Recommendations Machine learning models help Airbnb understand user preferences more accurately. The system continuously learns from user interactions and improves recommendations over time. For example, if a user frequently searches for beachside properties, Airbnb may start prioritizing similar listings automatically. This combination of machine learning and data engineering creates highly personalized user experiences. Why Data Engineering Matters in Modern Apps Recommendation systems require clean, fast, and scalable data pipelines. Without strong data engineering infrastructure, companies cannot process user behavior efficiently. Platforms like Airbnb depend heavily on data engineering to: This makes data engineering one of the most important technologies behind modern digital platforms. Airbnb uses modern data engineering systems to deliver personalized recommendations for millions of users worldwide. By combining real-time processing, cloud platforms, machine learning, and scalable pipelines, Airbnb improves user experience and booking efficiency continuously. As recommendation systems become more advanced in 2026, data engineering skills will remain highly valuable for building intelligent applications and large-scale digital platforms.

Top SQL Skills Every Data Engineer Must Learn
SQL is one of the most important skills in data engineering. Almost every modern company uses SQL to manage, process, analyze, and retrieve data from databases and cloud platforms. Whether companies use AWS, Azure, Snowflake, Databricks, or traditional databases, SQL remains a core technology for handling large-scale data systems. For aspiring data engineers, strong SQL skills are essential for building successful careers in 2026. In this article, we will understand the top SQL skills every data engineer must learn and why SQL is highly important in modern data engineering. Why SQL Is Important in Data Engineering Data engineers work with massive amounts of structured and semi-structured data every day. SQL helps engineers: Most cloud data platforms and big data systems also support SQL-based processing. Because of this, companies expect data engineers to have strong SQL knowledge. Understanding SQL Queries The first skill every data engineer must master is writing efficient SQL queries. This includes: Understanding how to retrieve and manipulate data correctly is the foundation of SQL. Joins and Relationships Data in companies is usually stored across multiple tables. Data engineers must understand different types of joins such as: Joins help combine data from multiple sources for analytics and reporting. This is one of the most commonly used SQL skills in real-world projects. SQL for ETL Pipelines SQL is heavily used in ETL processes. Data engineers use SQL to clean, transform, validate, and load data into warehouses or analytics systems. Understanding SQL transformations helps improve pipeline efficiency and data quality. Many platforms like Snowflake, Databricks, and BigQuery rely heavily on SQL-based workflows. Query Optimization Writing SQL queries is important, but writing optimized queries is even more valuable. Data engineers should understand: Efficient SQL queries reduce processing time and improve large-scale system performance. Working With Cloud Databases Modern data engineering mainly operates on cloud platforms. Engineers should learn SQL on platforms such as: Cloud SQL skills are highly valuable in today’s job market. SQL continues to be one of the most important skills for data engineers in 2026. From ETL pipelines and cloud analytics to reporting and large-scale processing, SQL is used everywhere in modern data systems. Data engineers who master SQL querying, joins, optimization, and cloud database technologies can build strong careers in the growing data engineering industry.

Best Data Engineering Projects for Freshers in 2026
Data engineering is becoming one of the fastest-growing technology careers in the world. Companies today generate massive amounts of data from mobile apps, websites, cloud systems, streaming platforms, and AI applications. Because of this, organizations need skilled data engineers who can build data pipelines, process information, and manage large-scale systems. For freshers entering the industry in 2026, building real-world projects is one of the best ways to learn practical skills and improve job opportunities. In this article, we will look at some of the best data engineering projects for beginners and why these projects are important for career growth. Why Projects Are Important for Freshers Learning theory alone is not enough in modern data engineering. Companies prefer candidates who understand how to work with real-world data systems, cloud platforms, ETL pipelines, and analytics tools. Projects help freshers: Hands-on projects also help students learn tools like SQL, Python, Apache Spark, Kafka, AWS, Azure, and Databricks more effectively. ETL Pipeline Project One of the best beginner projects is building an ETL pipeline. In this project, freshers can collect raw data from APIs, CSV files, or databases, clean the data using Python or Spark, and load it into a cloud database or data warehouse. This project helps beginners understand data ingestion, transformation, scheduling, and workflow automation. Real-Time Streaming Project Real-time streaming is becoming highly important in modern companies. Freshers can build a streaming pipeline using Apache Kafka and Spark Streaming to process live events continuously. For example, the project can simulate: This type of project demonstrates understanding of live data processing systems. Cloud Data Engineering Project Cloud platforms are now widely used in the industry. Freshers can build projects using AWS or Azure services such as: Cloud-based projects help students learn scalable infrastructure and modern data architecture. Data Warehouse Project Another excellent project is creating a mini data warehouse for business analytics. Freshers can collect sales or customer data, design tables, create SQL queries, and generate reports. This project improves SQL and data modeling skills. Building projects is one of the best ways for freshers to enter the data engineering industry in 2026. Projects provide practical exposure to ETL pipelines, cloud computing, streaming systems, and analytics workflows used in real companies. Freshers who work on hands-on projects and continuously improve their technical skills can build strong careers in modern data engineering.

Snowflake vs Databricks – Which Platform Is Better for Data Engineers?
Modern companies generate massive amounts of data every day from applications, websites, cloud systems, IoT devices, and streaming platforms. To process and analyze this data efficiently, organizations use modern cloud data platforms like Snowflake and Databricks. Both platforms are highly popular in the data engineering industry and are widely used by enterprises worldwide. In this article, we will understand the differences between Snowflake and Databricks, their features, use cases, and which platform is better for data engineers in 2026. What Is Snowflake? Snowflake is a cloud-based data warehouse platform designed mainly for data storage, SQL analytics, and business intelligence workloads. It allows companies to store structured and semi-structured data in a scalable cloud environment. Snowflake is known for: Many organizations use Snowflake for reporting, dashboards, and large-scale business analytics. What Is Databricks? Databricks is a cloud-based data engineering and analytics platform built around Apache Spark. It is mainly used for: Databricks supports multiple programming languages such as Python, SQL, Scala, and R. It is highly popular among data engineers, machine learning engineers, and data scientists. Snowflake vs Databricks – Major Differences Snowflake mainly focuses on data warehousing and analytics. Databricks focuses more on big data engineering, machine learning, and advanced data processing. Snowflake is easier for SQL users and business analytics teams because it requires less infrastructure management. Databricks is more powerful for handling large-scale ETL pipelines, streaming systems, and AI-driven workloads. Another major difference is processing architecture. Snowflake uses cloud-native storage and compute separation, while Databricks uses Apache Spark-based distributed processing. Which Platform Is Better for Data Engineers? The answer depends on project requirements. If the company mainly needs: then Snowflake becomes a strong choice. If the organization handles: then Databricks is usually more suitable. Many modern enterprises now use both platforms together. Why Both Platforms Are Trending in 2026 As cloud adoption grows rapidly, companies need scalable platforms capable of handling massive datasets efficiently. Snowflake simplifies cloud analytics, while Databricks supports advanced engineering and AI workloads. This combination makes both platforms highly valuable in modern data engineering ecosystems. Learning Snowflake and Databricks can provide excellent career opportunities for aspiring data engineers in 2026. Snowflake and Databricks are two of the most important platforms in modern data engineering. Snowflake is highly effective for cloud analytics and business intelligence, while Databricks excels in big data processing, machine learning, and real-time engineering workloads. For data engineers, understanding both platforms can create strong career growth opportunities in cloud and big data technologies.

AI Agents in Data Engineering – How Autonomous Pipelines Work in 2026
Artificial Intelligence is rapidly transforming the world of data engineering. Earlier, data pipelines required continuous manual monitoring, scheduling, debugging, and maintenance by engineers. Today, AI-powered agents are helping automate many of these tasks. Modern companies are now building autonomous data pipelines that can monitor, optimize, and repair themselves automatically using AI agents. In this article, we will understand what AI agents are, how autonomous pipelines work, and why AI is becoming important in data engineering in 2026. What Are AI Agents in Data Engineering? AI agents are intelligent software systems capable of making decisions automatically using machine learning, automation rules, and real-time monitoring. In data engineering, these agents help manage data pipelines without requiring constant human intervention. Instead of manually checking failures, delays, or performance issues, AI agents can detect problems instantly and take corrective actions automatically. This helps companies process data faster and reduce operational workload. What Are Autonomous Data Pipelines? Autonomous pipelines are self-managing data workflows capable of handling data ingestion, transformation, monitoring, optimization, and recovery automatically. Traditional pipelines usually require engineers to: Autonomous systems use AI agents to automate many of these operations intelligently. How AI Agents Improve Data Pipelines AI agents can continuously monitor pipeline performance and detect anomalies in real time. If a data pipeline slows down or fails, the AI system can automatically restart services, reroute workloads, or allocate additional cloud resources. AI agents also help optimize query performance, resource utilization, and ETL workflows. In streaming systems, autonomous pipelines can process large-scale real-time events with minimal human involvement. This is becoming highly useful for platforms handling millions of users daily. Technologies Used in Autonomous Pipelines Modern AI-driven data engineering systems use technologies such as: Cloud platforms like AWS, Azure, and Google Cloud also provide AI-powered monitoring and automation tools. These technologies help organizations build scalable and intelligent data platforms. Why AI in Data Engineering Is Growing Modern businesses generate massive amounts of data every second. Managing large-scale pipelines manually becomes difficult and expensive. AI agents reduce downtime, improve reliability, and automate repetitive operational tasks. Companies also benefit from faster analytics, improved scalability, and reduced infrastructure management efforts. This is one reason why AI-driven data engineering is becoming a major trend in 2026. AI agents are changing how modern data engineering systems operate. Autonomous pipelines can monitor, optimize, and repair workflows automatically, helping companies process data more efficiently at scale. As AI adoption grows, data engineers who understand automation, cloud platforms, and intelligent pipeline systems will have strong career opportunities in the future. Learning AI-driven data engineering concepts today can help engineers stay competitive in the rapidly evolving technology industry.

Why Cloud Computing Is Important for Data Engineering in 2026
Data engineering is changing rapidly as companies generate huge amounts of data every day. From mobile applications and payment systems to streaming platforms and cloud applications, businesses now depend on fast and scalable data systems. Traditional servers alone are no longer enough to handle modern data workloads efficiently. This is why cloud computing has become one of the most important technologies in data engineering. In this article, we will understand why cloud computing is important for data engineers, how companies use cloud platforms, and which cloud skills are valuable in 2026. What Is Cloud Computing? Cloud computing means using internet-based services for storing, processing, and managing data instead of relying only on physical servers. Cloud platforms provide resources like: Popular cloud providers include AWS, Microsoft Azure, and Google Cloud Platform. These platforms allow companies to scale infrastructure quickly without purchasing expensive hardware. Why Data Engineers Use Cloud Platforms Modern businesses process massive amounts of structured and unstructured data every second. Cloud computing helps data engineers build scalable systems capable of handling this growing data efficiently. Instead of manually managing servers, engineers can focus on building ETL pipelines, analytics systems, and real-time processing architectures. Cloud platforms also improve deployment speed and reduce infrastructure maintenance costs. Common Cloud Services Used in Data Engineering Data engineers use several cloud services daily. Storage services like Amazon S3 and Azure Data Lake help manage large-scale datasets. ETL services such as AWS Glue and Azure Data Factory automate data movement and transformation. Big data tools like Databricks, EMR, and BigQuery process huge datasets efficiently. Streaming services including Kafka, Kinesis, and Pub/Sub support real-time data pipelines. These services make cloud computing highly important in modern data engineering projects. Benefits of Cloud Computing One major advantage is scalability. Cloud platforms allow companies to increase or reduce resources instantly depending on workload requirements. Another benefit is cost optimization. Businesses only pay for the services they use instead of investing heavily in physical infrastructure. Cloud systems also provide better reliability, backup management, and disaster recovery solutions. Cloud computing has become a core part of modern data engineering. Companies worldwide are migrating toward cloud platforms to process massive amounts of data efficiently and support real-time analytics systems. For aspiring data engineers, learning cloud technologies like AWS, Azure, and Google Cloud can create excellent career opportunities in 2026 and beyond. Understanding cloud computing, ETL pipelines, and big data processing together can help build a strong foundation for a successful data engineering career.

On-Premise vs AWS in Data Engineering – Which One Is Better in 2026?
Data engineering has evolved rapidly over the last few years. Earlier, companies mainly depended on traditional on-premise infrastructure to store and process data. Today, many organizations are moving toward cloud platforms like AWS because of flexibility, scalability, and faster deployment. Still, both On-Premise and AWS environments are widely used in real-world data engineering projects. In this article, we will understand the difference between On-Premise systems and AWS cloud platforms, how data engineers work in both environments, and why learning an On-Premise course along with AWS skills can help build a strong career in data engineering. What Is On-Premise Infrastructure? On-Premise infrastructure means all servers, storage systems, databases, and networking devices are managed inside the company’s own physical data center. Traditional enterprises, banks, healthcare companies, and government organizations often prefer on-premise systems because they want complete control over their data and security. In an on-premise environment, data engineers handle: Although on-premise systems offer better control, they require expensive hardware and maintenance teams. What Is AWS in Data Engineering? AWS (Amazon Web Services) is a cloud platform that allows companies to store, process, and analyze data without maintaining physical infrastructure. Instead of purchasing servers, organizations can use cloud services whenever needed. Popular AWS services used in data engineering include: AWS helps companies scale quickly while reducing infrastructure costs. Modern startups and technology companies heavily rely on AWS because deployment and scaling become much easier. Major Differences Between On-Premise and AWS The biggest difference is infrastructure management. In on-premise systems, companies manage hardware manually. In AWS, cloud services handle most infrastructure operations automatically. Scalability is also different. On-premise systems require additional hardware purchases when data grows, while AWS resources can scale instantly. Cost structure varies as well. On-premise setups require high upfront investment, whereas AWS follows a pay-as-you-use pricing model. AWS also provides faster deployment compared to traditional data center environments. Which Skills Should Data Engineers Learn? In 2026, cloud knowledge is becoming extremely important for data engineering careers. Most companies now expect engineers to understand AWS services, cloud ETL pipelines, big data processing, and real-time streaming systems. At the same time, understanding traditional infrastructure is also valuable because many enterprises still use hybrid environments. Learning both cloud and traditional systems gives better career opportunities. A good learning path includes: Both On-Premise infrastructure and AWS cloud platforms are important in modern data engineering. Traditional organizations continue using on-premise systems for compliance and security, while modern companies prefer AWS for scalability and flexibility. For aspiring data engineers, learning both environments can create strong job opportunities in 2026 and beyond.

Best Data Engineering Courses to Learn in 2026
Data engineering is becoming one of the fastest-growing careers in the technology industry. Companies today generate massive amounts of data from websites, mobile apps, payment systems, IoT devices, cloud platforms, and AI applications. To manage this data efficiently, organizations need skilled data engineers. If you want to build a successful career in this field, choosing the right data engineering courses is very important. Good courses help beginners understand databases, cloud platforms, ETL pipelines, big data tools, and real-world project development. In this article, we will look at some of the best data engineering courses and technologies that are important in 2026. Why Learn Data Engineering? Modern companies like Netflix, Amazon, Uber, Swiggy, and Spotify depend heavily on data engineering systems. Data engineers help businesses collect, process, transform, and analyze large-scale data efficiently. Learning data engineering can help you: Because demand is increasing rapidly, many students and working professionals are now learning data engineering technologies. Important Skills Covered in Data Engineering Courses Most modern data engineering courses focus on practical industry skills. These include: SQL and Databases SQL is one of the most important skills for data engineers. It is used to manage and query structured data. Python Programming Python is widely used for automation, ETL development, data processing, and analytics. Big Data Technologies Tools like Apache Spark, Hadoop, and Kafka help process massive datasets efficiently. Cloud Platforms Cloud technologies such as AWS, Azure, and Google Cloud are heavily used in modern data engineering projects. ETL and Data Pipelines Students learn how to build systems that extract, transform, and load data from multiple sources. Popular Data Engineering Courses in 2026 Some of the most valuable learning areas include: Practical project-based training is becoming more important than theoretical learning. Importance of Real-Time Projects Many companies prefer candidates with hands-on project experience. Real-world projects help students understand how modern systems work in production environments. Projects may include: These projects improve practical understanding and job readiness. Data engineering is creating huge career opportunities worldwide. As companies continue generating large amounts of data, the need for skilled data engineers will continue growing in 2026 and beyond. Learning the right technologies, cloud platforms, and real-world project skills can help students build a strong career in this industry. Choosing practical, project-oriented data engineering courses can make a big difference in getting industry-ready quickly.
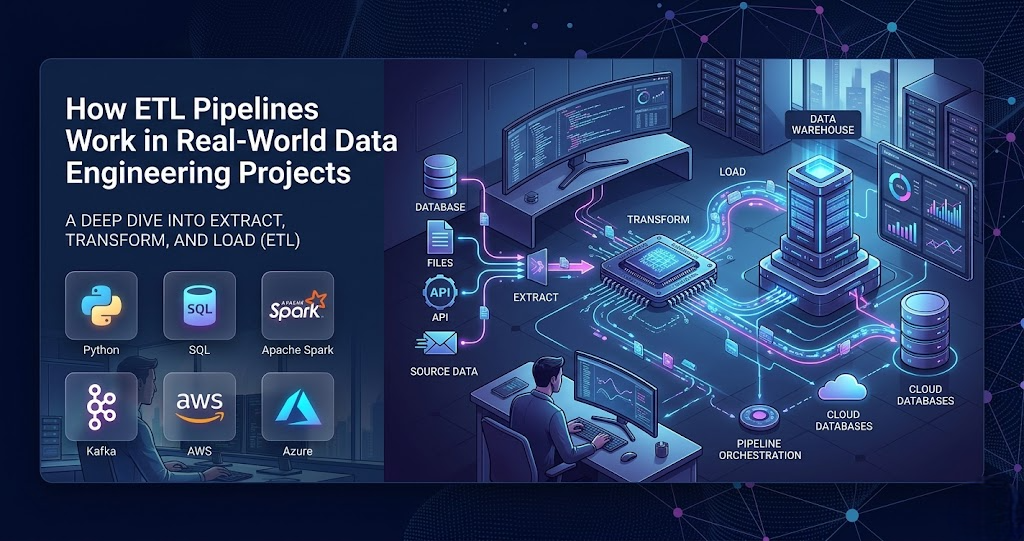
How ETL Pipelines Work in Real-World Data Engineering Projects
Modern companies generate huge amounts of data every day from websites, mobile applications, payment systems, cloud platforms, and IoT devices. However, raw data alone is not useful unless it is properly collected, cleaned, and stored for analytics. This is where ETL pipelines become important in data engineering. ETL stands for Extract, Transform, and Load. These pipelines help organizations move data from multiple sources into centralized systems where businesses can analyze and use the information effectively. Companies like Amazon, Netflix, Swiggy, Uber, and Spotify depend heavily on ETL pipelines to manage large-scale data processing operations. What Is an ETL Pipeline? An ETL pipeline is a process that collects data from different systems, transforms the data into a usable format, and loads it into a database or data warehouse. The three main stages are: Extract In this stage, data is collected from various sources such as: Data engineers gather information from multiple systems continuously. Transform Raw data often contains duplicates, errors, missing values, or inconsistent formats. During transformation, data engineers: This stage is extremely important because poor-quality data can lead to incorrect business decisions. Load After transformation, the processed data is loaded into systems such as: Businesses then use this data for reporting, machine learning, and decision-making. Real-World Example of ETL Pipelines Imagine a food delivery company like Swiggy. Every second, users place orders, track delivery agents, make payments, and leave reviews. This data comes from different applications and systems. ETL pipelines collect all this information, process it, and store it in centralized analytics platforms. The company can then analyze: This helps businesses improve customer experience and operational efficiency. Popular ETL Tools Used in Data Engineering Modern data engineers use several ETL tools to automate data workflows. Popular technologies include: Cloud-based ETL tools are especially popular because they provide scalability and automation. Why ETL Pipelines Matter Without ETL pipelines, businesses would struggle to manage growing amounts of data efficiently. ETL systems help companies: As companies continue generating larger datasets every day, ETL pipelines have become one of the most important components in modern data engineering. ETL pipelines are the backbone of modern data engineering systems. They help businesses collect, process, and organize massive amounts of information from multiple sources efficiently. For aspiring data engineers, learning ETL concepts and tools is one of the best ways to build strong real-world skills and grow a successful career in data engineering.

How Spotify and YouTube Handle Millions of Streaming Events in Real Time
Spotify and YouTube process massive amounts of streaming data every second to deliver recommendations, analytics, and smooth user experiences. Every second, millions of users stream songs on Spotify and videos on YouTube. What feels instant to users is actually powered by massive real-time data engineering systems working continuously in the background. Whenever someone plays a song, skips music, watches a video, searches for content, or clicks a recommendation, streaming events are generated immediately. These events are processed within seconds to improve recommendations, monitor performance, personalize feeds, and deliver smooth streaming experiences. Modern streaming platforms cannot wait hours to process data in batches. User behavior changes every second, and platforms must respond instantly. This is why companies like Spotify and YouTube heavily depend on real-time data processing technologies. What Is Real-Time Streaming Data? Real-time streaming data refers to continuously generated information that is processed instantly as it arrives. For streaming platforms, data flows constantly from mobile apps, smart TVs, desktops, advertisements, recommendation engines, and user interactions. Instead of storing data first and processing it later, systems analyze events immediately. This allows platforms to react quickly and improve user experiences in real time. How Spotify Uses Real-Time Data Spotify handles billions of streaming events daily from users around the world. Every user interaction creates live data that flows through distributed streaming systems. When users listen to music, Spotify instantly tracks listening behavior, song preferences, skips, playlist activity, and search patterns. This helps the platform generate personalized recommendations such as Discover Weekly and Daily Mix playlists. Spotify also uses live data to identify trending songs and monitor regional listening activity. If a song suddenly becomes popular, Spotify systems can detect the trend immediately and promote it to more users. Another major use of streaming data is advertisement targeting. Spotify analyzes user activity in real time to deliver relevant audio advertisements based on listening patterns and engagement. To handle these workloads, Spotify uses technologies like Apache Kafka, Apache Flink, Kubernetes, and cloud-based analytics systems. How YouTube Processes Streaming Events YouTube receives enormous amounts of streaming data every second from billions of video views globally. Whenever users watch videos, pause content, like videos, comment, or subscribe to channels, live events are generated continuously. These events help YouTube improve recommendations and maintain platform quality. One of YouTube’s most important systems is its recommendation engine. As users interact with videos, machine learning models instantly analyze viewing history, watch time, and engagement behavior to suggest more relevant content. YouTube also processes streaming data for creator analytics. Content creators can see near real-time updates about views, audience retention, engagement, and subscriber growth. In addition, YouTube uses streaming systems to detect spam, fake views, suspicious activity, and policy violations quickly before they impact the platform. Google technologies such as Pub/Sub, Dataflow, Bigtable, and TensorFlow help power YouTube’s real-time infrastructure. Technologies Behind Streaming Platforms Streaming companies rely on distributed data engineering systems to process high-speed events efficiently. Apache Kafka is commonly used for collecting and transporting streaming events between services. Frameworks like Apache Flink and Spark Streaming process data continuously with very low latency. Cloud platforms such as AWS, Azure, and Google Cloud provide scalable infrastructure capable of handling billions of events daily. Machine learning systems also play a major role by analyzing live user behavior and improving personalization continuously. Challenges in Real-Time Streaming Systems Processing streaming data at global scale is extremely challenging. Platforms must maintain low latency while handling billions of events from users worldwide. Infrastructure must scale automatically during traffic spikes while ensuring system reliability and fault tolerance. Even small delays can negatively impact recommendations, analytics, and user experience. Data consistency is another major challenge because information is generated simultaneously from millions of devices and locations. Why Real-Time Data Engineering Matters Real-time data engineering is the foundation of modern streaming platforms. Without it, recommendations would become outdated, analytics would be delayed, and users would experience slower and less personalized services. Streaming systems allow companies to understand user behavior instantly and respond continuously with better recommendations, smoother playback, and improved engagement. Spotify and YouTube are excellent examples of how modern companies use real-time data engineering at massive scale. Every interaction on these platforms generates streaming events that are processed instantly using technologies like Kafka, Flink, Spark Streaming, cloud infrastructure, and machine learning systems. As streaming platforms continue growing in 2026 and beyond, real-time data engineering will remain one of the most important skills for future data engineers.
