

Modern companies generate huge amounts of data every day from websites, mobile applications, payment systems, cloud platforms, and IoT devices. However, raw data alone is not useful unless it is properly collected, cleaned, and stored for analytics.
This is where ETL pipelines become important in data engineering.
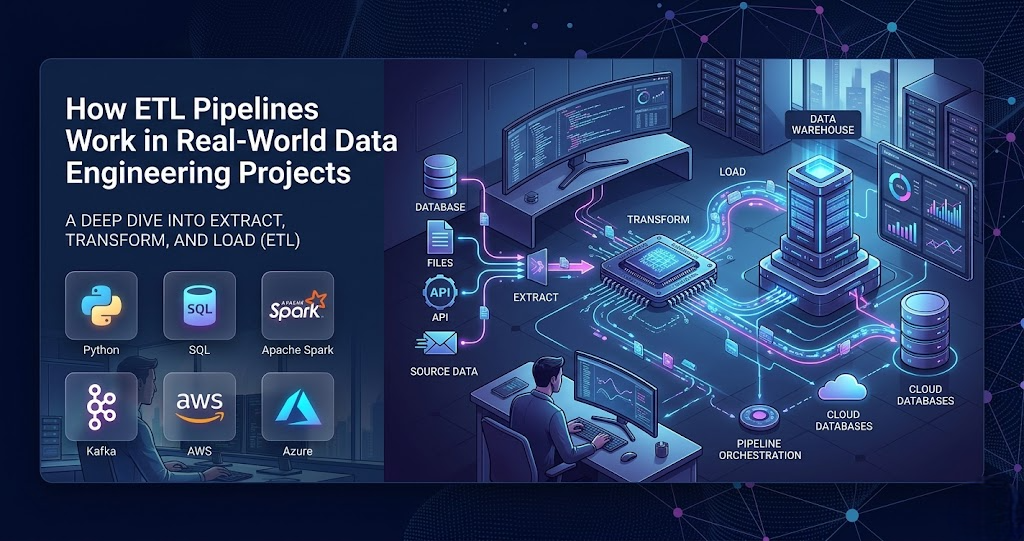
ETL stands for Extract, Transform, and Load. These pipelines help organizations move data from multiple sources into centralized systems where businesses can analyze and use the information effectively.
Companies like Amazon, Netflix, Swiggy, Uber, and Spotify depend heavily on ETL pipelines to manage large-scale data processing operations.
What Is an ETL Pipeline?
An ETL pipeline is a process that collects data from different systems, transforms the data into a usable format, and loads it into a database or data warehouse.
The three main stages are:
Extract
In this stage, data is collected from various sources such as:
- websites,
- mobile apps,
- APIs,
- cloud storage,
- databases,
- transaction systems.
Data engineers gather information from multiple systems continuously.
Transform
Raw data often contains duplicates, errors, missing values, or inconsistent formats.
During transformation, data engineers:
- clean the data,
- remove duplicates,
- standardize formats,
- apply business rules,
- prepare data for analytics.
This stage is extremely important because poor-quality data can lead to incorrect business decisions.
Load
After transformation, the processed data is loaded into systems such as:
- data warehouses,
- data lakes,
- analytics platforms,
- reporting dashboards.
Businesses then use this data for reporting, machine learning, and decision-making.
Real-World Example of ETL Pipelines
Imagine a food delivery company like Swiggy.
Every second, users place orders, track delivery agents, make payments, and leave reviews. This data comes from different applications and systems.
ETL pipelines collect all this information, process it, and store it in centralized analytics platforms. The company can then analyze:
- delivery performance,
- customer behavior,
- restaurant ratings,
- payment trends.
This helps businesses improve customer experience and operational efficiency.
Popular ETL Tools Used in Data Engineering
Modern data engineers use several ETL tools to automate data workflows.
Popular technologies include:
- Apache Airflow,
- AWS Glue,
- Azure Data Factory,
- Talend,
- Informatica,
- Apache Spark.
Cloud-based ETL tools are especially popular because they provide scalability and automation.
Why ETL Pipelines Matter
Without ETL pipelines, businesses would struggle to manage growing amounts of data efficiently.
ETL systems help companies:
- organize data properly,
- automate workflows,
- improve analytics accuracy,
- support machine learning systems,
- make faster business decisions.
As companies continue generating larger datasets every day, ETL pipelines have become one of the most important components in modern data engineering.
ETL pipelines are the backbone of modern data engineering systems. They help businesses collect, process, and organize massive amounts of information from multiple sources efficiently.
For aspiring data engineers, learning ETL concepts and tools is one of the best ways to build strong real-world skills and grow a successful career in data engineering.



