

Modern applications generate billions of data events every day from user activity, mobile apps, cloud systems, and streaming platforms.
Platforms like Netflix, Amazon, Uber, YouTube, and Instagram process billions of data events daily to provide smooth user experiences and intelligent recommendations.
Whenever you:
- watch a video,
- search for a product,
- book a ride,
- click a notification,
- or make an online payment,
a data event is created behind the scenes.
Managing billions of these events efficiently is one of the biggest challenges in modern data engineering.
In this blog, you will understand how companies process huge-scale data events using real-time pipelines, distributed systems, and cloud technologies.
What Are Data Events?
A data event is any user or system activity generated inside an application.
Examples include:
- User logins
- Product searches
- Video streaming activity
- GPS location updates
- Payment transactions
- Clickstream data
- Notifications
- API requests
Every action creates valuable information that companies use for analytics, recommendations, monitoring, and business decisions.
Why Companies Process Data Events in Real Time
Modern businesses cannot wait several hours to analyze user activity.
Real-time systems help companies:
- detect fraud instantly,
- recommend products immediately,
- optimize app performance,
- monitor systems continuously,
- and personalize customer experiences.
For example:
- Uber updates ride tracking in real time.
- Netflix recommends movies instantly.
- Amazon adjusts recommendations dynamically.
- Banking apps detect suspicious transactions immediately.
This is why real-time event processing has become critical in modern applications.
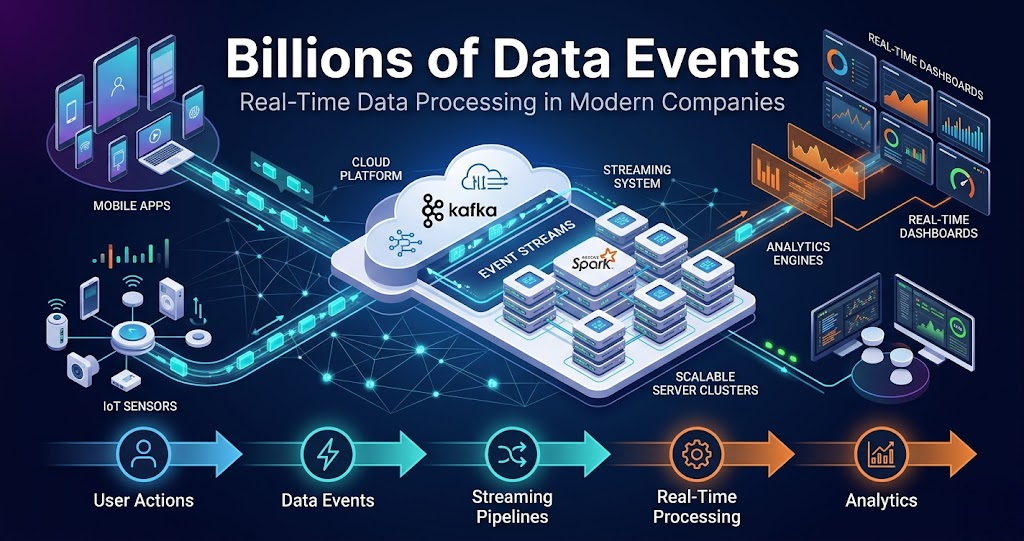
How Data Events Move Through Systems
A modern data pipeline usually works like this:
User Activity → Event Streaming → Processing Engine → Storage → Analytics Dashboard
Whenever a user interacts with an application:
- Events are generated
- Streaming systems collect the events
- Processing engines analyze the data
- Results are stored in cloud platforms
- Dashboards and applications use the processed information
This entire process often happens within seconds.
Technologies Used for Event Processing
Modern companies use distributed technologies to handle billions of events efficiently.
Popular technologies include:
- Apache Kafka
- Apache Spark
- Databricks
- AWS Kinesis
- Azure Event Hub
- AWS Glue
- Snowflake
- Cloud Storage Systems
These tools help organizations build scalable and fault-tolerant data pipelines.
Role of Apache Kafka
Apache Kafka is one of the most widely used event streaming platforms.
Kafka helps companies:
- collect streaming data,
- handle high event volume,
- and move data between systems reliably.
For example:
- Netflix streams viewing activity through Kafka
- Uber processes ride updates using streaming systems
- Amazon handles customer activity events continuously
Kafka acts like a central highway for moving real-time data across applications.
Role of Apache Spark
Apache Spark helps process huge-scale data quickly.
Spark can:
- clean data,
- transform events,
- run analytics,
- and process streaming pipelines.
Many companies combine Kafka and Spark together for real-time analytics systems.
Spark is highly popular because it processes massive datasets much faster than traditional systems.
Importance of Cloud Platforms
Cloud platforms make large-scale event processing easier and more scalable.
Cloud providers like:
- AWS
- Azure
- Google Cloud
offer services that help companies:
- scale automatically,
- reduce infrastructure management,
- and process huge workloads efficiently.
Modern data engineering heavily depends on cloud computing because data volume keeps growing rapidly.
Challenges in Processing Billions of Events
Handling huge-scale data systems is not easy.
Companies face challenges like:
- high processing latency,
- data loss prevention,
- infrastructure scaling,
- system failures,
- and data quality issues.
To solve these problems, businesses use distributed architectures and monitoring systems.
Data engineers play an important role in building stable and scalable pipelines.
Why This Matters for Data Engineers
Modern data engineering jobs are heavily focused on:
- real-time pipelines,
- distributed systems,
- streaming architectures,
- and cloud platforms.
Companies are actively looking for engineers who understand:
- Spark,
- Kafka,
- cloud services,
- ETL pipelines,
- and large-scale analytics systems.
As businesses generate more data every year, demand for these skills continues growing rapidly.
Modern companies process billions of data events every day to deliver fast, intelligent, and personalized digital experiences.
From streaming platforms and ride-sharing apps to e-commerce systems and banking applications, real-time event processing powers modern technology infrastructure.
Technologies like Kafka, Spark, cloud computing, and distributed pipelines are becoming essential in the world of data engineering.
This is why learning modern big data and real-time processing technologies can create strong career opportunities in 2026 and beyond.



