


Many people who are planning to enter the tech field often ask one important question: Is data engineering a good career in 2026? With the rapid growth of data in every industry, this question has become more relevant than ever. The short answer is yes. Data engineering is one of the fastest-growing and most in-demand careers today. Companies rely heavily on data to make decisions, and without data engineers, it is not possible to build reliable data systems. However, to make the right career decision, it is important to understand salary, demand, and future growth in detail. Why Data Engineering Is in High Demand Every company today works with data. From startups to large enterprises, data is used for analytics, reporting, and machine learning. But raw data is often messy and unstructured. This is where data engineers play a key role. Data engineers build pipelines that collect, process, and store data in a usable format. As businesses continue to grow digitally, the need for data engineers is increasing. Some key reasons for high demand include: Because of these factors, companies are actively hiring skilled data engineers. Salary of Data Engineers in 2026 One of the biggest advantages of choosing data engineering as a career is the salary. Data engineers are among the highest-paid professionals in the tech industry. Salary depends on factors like experience, location, and skills. However, the general trend shows strong earning potential. Typical salary range: In countries like the US, UK, and India, data engineering salaries continue to grow each year due to increasing demand. Future Growth of Data Engineering The future of data engineering looks very strong. As more companies move to cloud platforms and adopt data-driven decision-making, the need for data engineers will continue to grow. New trends are also shaping the future: These trends show that data engineering is not just a temporary trend but a long-term career option. Skills Required for Data Engineering To succeed in this field, you need a combination of technical and practical skills. You don’t need to master everything at once, but you should build a strong foundation. Important skills include: With consistent learning and practice, these skills can be developed over time. Is Data Engineering Good for Beginners? Yes, data engineering is a good career even for beginners. However, it may feel slightly challenging at the start because of multiple concepts and tools. The key is to follow a structured approach. Start with basics like SQL and programming, then move to pipelines and tools. Avoid trying to learn everything at once. With proper guidance and regular practice, beginners can successfully enter this field. Challenges in Data Engineering Like any career, data engineering also has some challenges. Understanding these helps you prepare better. Common challenges include: These challenges become easier as you gain experience. So, is data engineering a good career in 2026? The answer is yes. It offers high demand, strong salary growth, and excellent future opportunities. While the learning process may feel challenging at the beginning, it becomes easier with the right approach. By focusing on fundamentals, practicing regularly, and building real-world skills, you can build a successful career in data engineering. If you are looking for a stable, high-growth, and future-proof career, data engineering is definitely a great choice.

Can You Become a Data Engineer Without Coding? The Truth
Many people who want to enter data engineering ask one common question: Do I need coding to become a data engineer? It’s a valid concern, especially for beginners coming from non-technical backgrounds. The honest answer is simple, you can start learning data engineering with little or no coding, but you cannot become a strong data engineer without coding in the long run. At the beginning, it may look like there are tools that allow you to build pipelines without writing code. Platforms like visual ETL tools, drag-and-drop interfaces, and cloud services make things easier. This gives the impression that coding is optional. But in real-world projects, coding becomes essential as complexity increases. Where You Can Start Without Coding It is possible to begin your journey without deep coding knowledge. Many beginner-friendly tools help you understand concepts like data flow, pipelines, and transformations without writing much code. You can start by learning: Some tools allow you to build pipelines visually. This helps you understand how data moves from source to destination. At this stage, your focus should be on concepts, not coding. Where Coding Becomes Important As you move forward, you will notice limitations in no-code or low-code tools. Real-world data engineering problems are not always simple. You may need to handle complex transformations, optimize performance, or fix pipeline failures. This is where coding becomes necessary. In real projects, coding is used for: Without coding, it becomes difficult to handle these tasks efficiently. Minimum Coding You Need The good news is that you do not need to become a software developer. Data engineering requires practical coding, not deep software engineering knowledge. The most important skills are: Even basic coding skills can take you far if you understand how data systems work. The Reality of Industry Expectations In real companies, data engineers are expected to write code. Even if you use tools like AWS Glue, Azure Data Factory, or Databricks, you will still write scripts, queries, or transformations. Most job descriptions clearly mention: This means coding is not optional if you want a job in this field. The Best Approach for Beginners Instead of avoiding coding, the better approach is to start small and build gradually. You don’t need to learn everything at once. A simple learning path: By following this step-by-step approach, coding will feel easier and more practical. Common Mistakes to Avoid Many beginners delay learning coding because they feel it is too hard. This slows down their progress. Common mistakes include: Coding becomes easier with practice. Avoiding it makes the journey harder. So, can you become a data engineer without coding? The truth is you can start without coding, but you cannot grow without it. Coding is a core skill in data engineering, but you only need practical knowledge, not deep programming expertise. If you take a step-by-step approach and focus on learning gradually, coding will stop feeling difficult. With consistency and practice, anyone can become a data engineer, even without a strong technical background at the beginning.

How to Start Data Engineering from Scratch (Step-by-Step Guide for Beginners 2026)
Starting data engineering from scratch can feel confusing, especially if you don’t know where to begin. There are many tools, technologies, and concepts, and most beginners feel overwhelmed. Many people start learning random tools without a clear path and end up getting stuck. The good news is that you don’t need to learn everything at once. If you follow a clear step-by-step approach, you can start learning data engineering easily, even with no prior experience. This guide will help you understand exactly what to learn and how to begin your journey in 2026. Understanding Data Engineering Before learning any tools, it is important to understand what data engineering actually is. Data engineering is the process of collecting, transforming, and storing data so that it can be used for analysis. In simple terms, data engineers build systems that move data from one place to another and make it ready for use. These systems are called data pipelines. Once you understand this basic idea, the rest of the learning process becomes much easier. Start with SQL SQL is the most important skill in data engineering. Almost every data engineer uses SQL daily to work with data. Without SQL, it becomes very difficult to move forward in this field. You should focus on learning: Strong SQL skills will make learning other tools much easier. Learn Basic Programming After SQL, the next step is to learn basic programming. Python is the most commonly used language in data engineering. You don’t need advanced coding skills, but you should be comfortable with basic concepts. Focus on understanding how to write simple programs, use functions, and work with data. Programming helps you build pipelines, automate tasks, and process data efficiently. Understand Data Pipelines Data pipelines are the core of data engineering. A pipeline is a system that takes data from a source, processes it, and stores it for analysis. A simple pipeline usually follows this flow: You should also understand concepts like ETL (Extract, Transform, Load) and the difference between batch and real-time processing. Learn Big Data Tools Once you understand the basics, you can start learning tools like Apache Spark. These tools are used to process large amounts of data efficiently. At the beginning, focus on understanding how data is read, transformed, and written using these tools. You don’t need to go deep immediately. Basic knowledge is enough to start. Learn Cloud Basics Most modern data engineering work happens on cloud platforms. It is important to learn at least one cloud platform such as AWS, Azure, or GCP. You should understand basic services like: Start with one platform and later expand your knowledge to others. Build Small Projects Learning theory alone is not enough. You need to build projects to understand how things work in real-world scenarios. Start with simple projects like reading data from a file, cleaning it, and storing it in a database. Then move to building basic pipelines and using cloud tools. Projects help you gain confidence and practical experience. Learn Real-World Concepts After gaining basic knowledge, you should start learning real-world concepts that are used in production systems. These include data quality, error handling, partitioning, and performance optimization. These topics help you understand how to build reliable and efficient data systems. Practice Regularly Consistency is the key to learning data engineering. You don’t need to study for long hours every day, but you should practice regularly. Even one to two hours daily can make a big difference. Focus on improving your SQL, coding skills, and understanding of pipelines. Regular practice helps you retain concepts and improve faster. Prepare for Jobs Once you have learned the basics and built some projects, you can start preparing for job opportunities. Focus on understanding concepts, solving SQL problems, and explaining how data pipelines work. It is also important to build a portfolio of your projects. This helps you showcase your skills and improves your chances of getting hired. Common Mistakes to Avoid Many beginners make mistakes that slow down their progress. Some of the most common mistakes include: Avoiding these mistakes will make your learning journey much smoother. Starting data engineering from scratch is not as difficult as it seems. The difficulty mostly comes from lack of direction, not from the field itself. If you follow a structured path and focus on basics, learning becomes much easier. Start with SQL and programming, understand data pipelines, and gradually move to tools and cloud platforms. Stay consistent, build projects, and keep improving step by step. Over time, you will develop the skills needed to become a data engineer.
Is Data Engineering Hard? A Complete Guide for Beginners in Data Engineering (2026)
Is data engineering hard? This is one of the most common questions beginners ask before starting their journey. The honest answer is, it can feel difficult at the beginning, but it is not impossible. Most people feel confused because there are many tools, technologies, and concepts to learn. This can make the field look complicated. But if you follow the right approach and learn step by step, data engineering becomes much easier over time. Why Data Engineering Feels Hard The main reason data engineering feels hard is because there are many things to learn. You need to understand SQL, some programming, data processing, and cloud platforms like AWS or Azure. Beginners often try to learn everything at once. This creates confusion and makes learning stressful. Instead of building strong basics, they jump between tools and lose clarity. Another reason is that most tutorials only explain tools. They do not show how everything works together in real projects. Because of this, many people struggle to understand how data flows in real systems. Also, in real-world projects, data is not always clean. You may face missing data, errors, or system failures. Without practice, these problems can feel difficult. But once you start working on real examples, these challenges become easier to handle. What Makes Data Engineering Easier Data engineering becomes easier when you focus on basics first. Instead of learning many tools, start with core concepts like how data moves from source to storage, how pipelines work, and how data is transformed. Once you understand these basics, learning tools becomes much faster and less confusing. It also helps to learn step by step: Practicing small projects regularly will improve your understanding. For example, you can build a simple pipeline that reads data, processes it, and stores it. These small steps build confidence. Over time, things that felt hard will become simple. Learning Curve in Data Engineering At the beginning, the learning curve can feel slow. You may not understand everything immediately, and that is normal. Many beginners feel stuck in the first few weeks because everything is new. But if you stay consistent, things start to make sense. After some time, concepts begin to connect. You will understand how systems work together, and learning becomes faster. Even experienced data engineers keep learning new tools and technologies. So you don’t need to know everything at once. Focus on progress, not perfection. Is Data Engineering Hard for Beginners? For beginners, data engineering can feel challenging in the beginning, especially if you are new to coding or databases. But it is completely possible to learn. The key is to: If you follow a structured path, learning becomes much easier. Also, learning from real examples and projects helps a lot. Instead of only reading theory, try to build something small. This will improve your understanding quickly. Common Mistakes Beginners Make Many beginners make a few common mistakes that make data engineering feel harder than it actually is. They try to learn too many tools at once, which leads to confusion. They also skip fundamentals like SQL and jump directly into advanced topics. Another mistake is not practicing enough. Without hands-on work, it is difficult to understand how things work in real scenarios. Avoiding these mistakes can make your learning journey much smoother. Data engineering is not too hard, but it does require effort and consistency. The difficulty depends on how you learn. If you try to learn everything at once, it will feel hard. But if you go step by step and focus on basics, it becomes manageable. Anyone can learn data engineering with the right approach. Start small, stay consistent, and keep practicing. Over time, you will gain confidence and build strong skills.onsistent, and keep practicing. Over time, you will gain confidence and build strong skills.

Why Your Spark Jobs Are Failing (And How to Fix Them Fast)
Apache Spark is one of the most widely used tools in data engineering, but many developers struggle with frequent job failures. These failures are not always due to complex issues; in most cases, they result from common mistakes in data handling, resource management, or pipeline design. Understanding why Spark jobs fail is essential because failures can delay pipelines, impact data reliability, and increase operational costs. This article explains the most common reasons behind Spark job failures and how to fix them quickly in real-world scenarios. Common Reasons Spark Jobs Fail One of the most frequent causes of Spark job failure is memory issues. Spark processes large volumes of data in distributed environments, and if executors do not have enough memory, jobs can crash with out-of-memory errors. This often happens when large datasets are collected into memory using operations like collect() or when improper partitioning leads to uneven data distribution. Another major reason is data skew. When data is not evenly distributed across partitions, some tasks take significantly longer than others, causing performance bottlenecks or even job failures. Skew typically occurs during joins or aggregations where certain keys have disproportionately large amounts of data. Incorrect configurations also lead to failures. Spark jobs rely heavily on configurations such as executor memory, number of cores, and shuffle partitions. Using default configurations without considering the data size or workload can result in inefficient execution or crashes. Dependency and environment issues are also common. Missing libraries, version mismatches, or incorrect cluster configurations can prevent Spark jobs from running successfully. This is especially common when deploying jobs across different environments like development, staging, and production. Data-related issues cannot be ignored. Corrupt files, schema mismatches, or unexpected null values can break transformations and cause job failures. Without proper validation, even a small inconsistency in data can propagate errors through the pipeline. How to Fix Spark Job Failures Quickly The first step in fixing Spark job failures is to monitor logs effectively. Spark provides detailed logs that help identify where and why a job failed. By analyzing executor logs and driver logs, you can quickly pinpoint issues such as memory errors, failed tasks, or data inconsistencies. Optimizing memory usage is critical. Avoid using operations that bring large datasets into memory, and instead use distributed processing techniques. Properly configure executor memory and use caching only when necessary to prevent memory overflow. Handling data skew is another important fix. Techniques such as salting keys, increasing partition counts, or using broadcast joins can help distribute data more evenly across nodes. This improves performance and reduces the risk of failures. Configuration tuning plays a key role in stability. Adjust parameters like spark.sql.shuffle.partitions, executor instances, and memory allocation based on workload requirements. Testing configurations with sample data before running full-scale jobs can prevent unexpected crashes. Data validation should be implemented early in the pipeline. Checking schema consistency, handling null values, and validating input data before processing can prevent failures later in the pipeline. This ensures that only clean and expected data is processed. Implementing retry mechanisms can help handle temporary failures. Network issues or transient errors can cause jobs to fail, but automatic retries allow the system to recover without manual intervention. Real-World Scenario Consider a data pipeline processing e-commerce transactions. If a Spark job fails due to data skew during a join operation, the pipeline may stop completely. By identifying the skewed key and applying techniques like salting or repartitioning, the issue can be resolved quickly. Similarly, if the job fails due to memory issues, adjusting executor memory and optimizing transformations can restore stability. These practical fixes ensure that pipelines continue running without major disruptions. Best Practices to Prevent Failures Preventing Spark job failures is more effective than fixing them later. Writing optimized queries, avoiding unnecessary shuffles, and using appropriate partitioning strategies can significantly improve job performance. Monitoring tools should be used to track job execution and detect issues early. Maintaining consistent environments and dependencies across systems also reduces unexpected failures. Most importantly, building pipelines with proper error handling and validation ensures long-term reliability. Spark job failures are common, but they are often predictable and preventable. By understanding the root causes such as memory issues, data skew, configuration problems, and data inconsistencies, data engineers can quickly resolve issues and build more stable pipelines. The key is to focus on monitoring, optimization, and validation. With the right approach, Spark can deliver highly efficient and reliable data processing at scale.
AWS vs Azure vs GCP: The Brutal Truth for Data Engineers (2026)
Choosing the right cloud platform is one of the most important decisions for any data engineer in 2026. With AWS, Azure, and GCP dominating the cloud ecosystem, the confusion is understandable. Each platform offers powerful tools, strong ecosystems, and growing demand in the job market. However, the real challenge is not just understanding the tools, but knowing which platform aligns with your career goals, learning curve, and real-world project requirements. This article breaks down the practical differences and gives you a clear, honest perspective on what actually matters. AWS, Azure, and GCP in Data Engineering AWS continues to lead the market with a wide range of mature data engineering services. Tools like S3, Glue, Redshift, and EMR are widely used in production environments. AWS is often the first choice for startups and large-scale data systems because of its flexibility and extensive documentation. However, the platform can feel complex for beginners due to the number of services and configurations involved. Azure has gained strong adoption, especially among enterprises that already use Microsoft products, and choosing between AWS and Azure depends on specific data engineering needs. Azure Data Factory, Synapse Analytics, and Azure Data Lake integrate well with tools like Power BI and other Microsoft services. This makes Azure a preferred choice for organizations that rely heavily on the Microsoft ecosystem. For learners, Azure can feel more structured and slightly easier to navigate compared to AWS. GCP focuses on simplicity and performance, particularly in analytics. BigQuery is one of the most powerful tools for data warehousing, offering fast query performance with minimal setup. Tools like Dataflow and Pub/Sub are well-designed for real-time processing. While GCP has fewer services compared to AWS, it often provides a more streamlined experience. However, its market share is smaller, which can impact job availability in certain regions. The Real Differences That Matter From a practical standpoint, the biggest differences are not just in tools, but in how each platform is used in real projects. AWS offers maximum flexibility but requires deeper understanding. Azure provides a more integrated experience, especially for enterprise workflows. GCP stands out for analytics and ease of use but has a narrower adoption base. Another important factor is the learning curve. AWS can be overwhelming at first, but mastering it gives you strong industry credibility. Azure is easier for those familiar with Microsoft tools. GCP is often the easiest to start with but may require additional effort to find opportunities depending on your location. Career Perspective for Data Engineers From a career standpoint, AWS currently offers the highest number of opportunities globally. Azure is rapidly growing in enterprise environments and is becoming equally valuable, especially in regions where Microsoft has a strong presence. GCP, while smaller, is highly valued in companies focused on advanced analytics and modern data architectures. Instead of trying to learn all three platforms at once, it is more effective to choose one platform, build strong fundamentals, and then expand your knowledge gradually. Many core concepts like data pipelines, storage, and processing remain the same across platforms. There is no single best cloud platform for data engineering. The right choice depends on your goals, background, and the type of projects you want to work on. AWS is ideal for flexibility and scale, Azure is strong in enterprise integration, and GCP excels in analytics and simplicity. The most important step is to start with one platform, gain hands-on experience, and focus on building real-world data pipelines. In the end, your understanding of data engineering concepts will matter more than the platform itself.

Why Everyone is Switching to Delta Lake in 2026
Traditional data lakes aren’t enough to meet modern demands for data, because the field is evolving so fast. Today’s organizations need systems that can handle real-time processing, ensure data reliability, and scale efficiently. Here’s where Delta Lake is a game-changer. More companies than ever are switching from data lakes to data warehouses in 2026 since they combine the flexibility of data lakes with the reliability of data warehouses. What is Delta Lake and Why It Matters With Delta Lake, you can add ACID transactions, schema enforcement, and time travel capabilities to existing data lakes. Unlike traditional data lakes, Delta Lake ensures that data is accurate and reliable. Because of this, it’s a vital part of modern data architectures, especially for companies that deal with a lot of data. Key Reasons Behind the Shift to Delta Lake Delta Lake’s ACID support is one of the main reasons it’s so popular. Traditionally, data lakes can get corrupted by concurrent writes and failures. All operations in Delta Lake are atomic and consistent, so you don’t have to worry about data reliability. Users can also access previous versions of data with its time travel feature. You can use this to debug data pipelines, audit changes, and recover from errors without losing data. In data lake environments, it’s hard to get control and transparency. Adoption is also driven by schema enforcement and evolution. By preventing invalid or unexpected data from being written, Delta Lake reduces pipeline breaks. It’s flexible enough to handle changing business requirements, while allowing schemas to evolve over time. Performance improvements make it even more popular. The speed and efficiency of queries are greatly improved by features like data skipping, file compression, and optimization techniques. By using a single system for multiple use cases, Delta Lake can handle batch and real-time workloads, simplifying data architecture for organizations. Real-World Applications Across industries, Delta Lake is used for building scalable and reliable data solutions. Real-time analytics, fraud detection systems, machine learning pipelines, and large-scale ETL processes use it. Streaming and batch data can be handled simultaneously while maintaining data consistency. Why You Should Learn Delta Lake in 2026 Delta Lake has become an essential skill for data engineers as companies adopt modern data architectures. With cloud platforms like AWS, Azure, and GCP, it integrates seamlessly with tools like Apache Spark. The Delta Lake course not only enhances your technical skills, but makes you more marketable. Delta Lake is a significant advancement in data engineering, addressing many of the limits of traditional data lakes. Providing reliable, high-performance, and scalable data processing, it’s a foundational technology in modern data systems. A growing adoption of Delta Lake in 2026 shows it’s not just a trend, but a long-term shift in data platforms.

Delta Lake Explained (Databricks) – Complete Guide for Data Engineers 2026
Delta Lake Explained in Databricks – Features, Architecture, and Use Cases Introduction Trying to understand Delta Lake in Databricks but getting confused how it is used in real data engineering projects? You’re not alone. Most people: But when asked why Delta Lake is needed and how it solves real problems, they get stuck. Because knowing features is not equal to understanding how data is managed in real pipelines. In this blog, you’ll understand: What is Delta Lake? Delta Lake is a storage layer built on top of data lakes. It improves data reliability and performance. In simple terms: Delta Lake makes data lakes behave like databases. Delta Lake adds reliability, consistency, and performance to data stored in data lakes. Why Delta Lake is Needed Problems without Delta Lake: Delta Lake solves these issues. Key Features of Delta Lake ACID Transactions Ensures reliable data operations Schema Enforcement Prevents invalid data Schema Evolution Allows schema changes Time Travel Access previous versions of data Data Versioning Tracks changes over time Step-by-Step Delta Lake in Databricks Step 1: Data Storage (Raw Data) Data is stored in data lake: Initially stored as files. Step 2: Convert to Delta Format Data is converted into Delta format. This adds: Step 3: Data Processing Databricks processes data: Step 4: Manage Updates Delta Lake allows: Without rewriting full data. Step 5: Version Control Every change is tracked. You can: Step 6: Query Optimization Delta improves performance: How Delta Lake Fits in Data Pipeline Typical flow: Real-World Example E-commerce pipeline: Delta Lake vs Traditional Data Lake Traditional Data Lake: Delta Lake: Common Mistakes
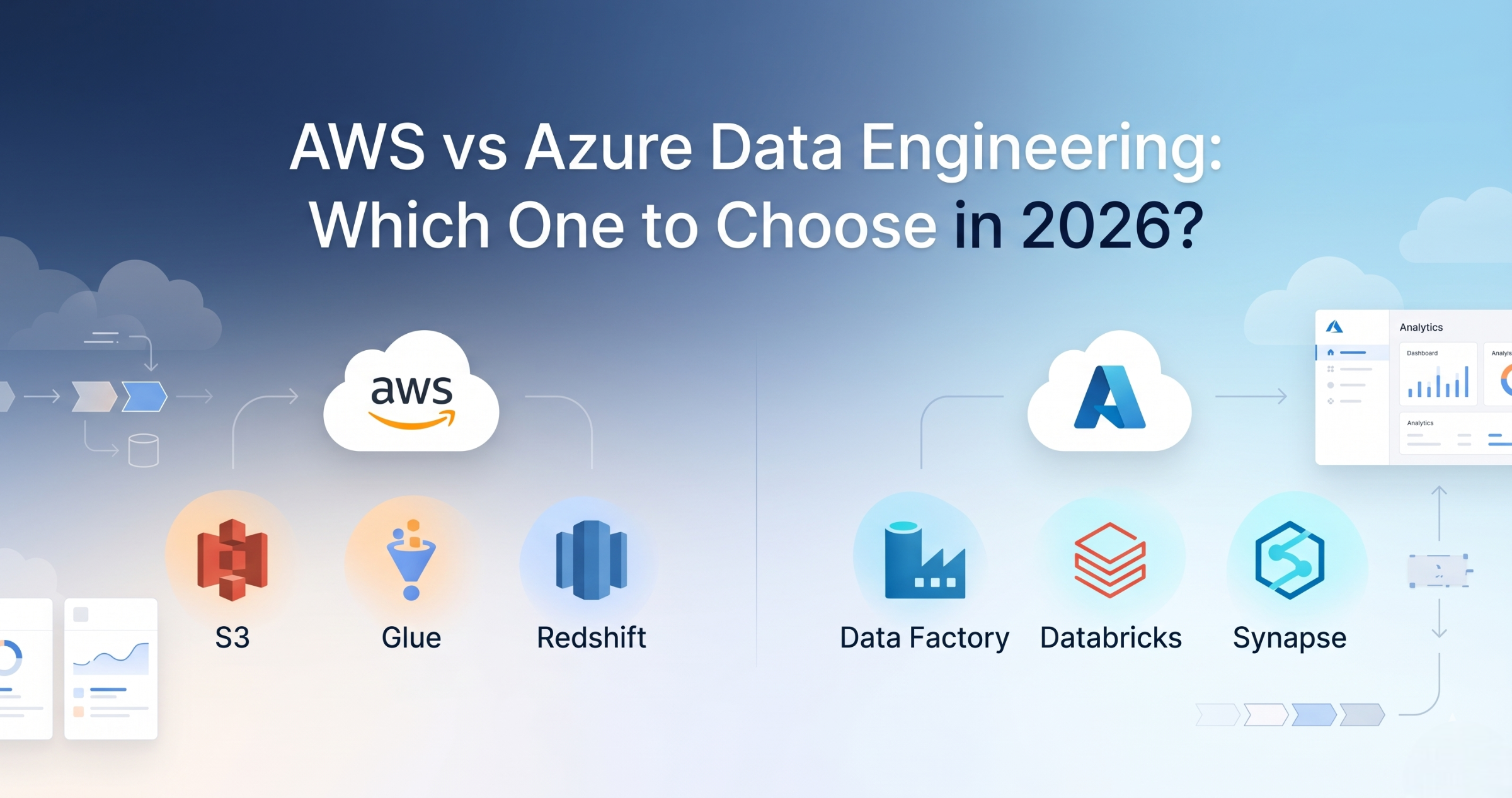
AWS vs Azure Data Engineering – Career Comparison (Which One to Choose in 2026)
Introduction Trying to choose between AWS and Azure for Data Engineering but feeling confused? You’re not alone. Most people: But when deciding which one to choose for career, they get stuck. Because knowing tools is not equal to knowing which path is better for your career. In this blog, you’ll understand: AWS and Azure both provide similar data engineering services, but AWS is more widely used, while Azure is strong in enterprise environments. What is AWS Data Engineering? AWS Data Engineering uses cloud services like: Used for building data pipelines on AWS cloud. What is Azure Data Engineering? Azure Data Engineering uses services like: Used for building pipelines on Azure cloud. AWS vs Azure Data Engineering Difference AWS: Azure: AWS vs Azure Services Mapping Storage: Processing: Orchestration: Warehouse: Career Opportunities AWS: Azure: Salary Comparison Both offer similar salary ranges. Depends on: No major difference in pay. Learning Curve AWS: Azure: Which One Should You Choose? Choose AWS if: Choose Azure if: Best Approach (Real Advice) Don’t choose only one. Start with AWS → Then learn Azure basics. Because in real projects: Companies expect multi-cloud knowledge. Real-World Scenario Company setup: Same concepts apply in both AWS and Azure. Common Mistakes

Partitioning & Bucketing in Hive – Complete Guide (Real Scenarios 2026)
Introduction Trying to understand partitioning and bucketing in Hive but getting confused? You’re not alone. Most people: But when asked how to optimize Hive queries using partitioning and bucketing, they get stuck. Because knowing Hive is not equal to knowing how data is stored and accessed efficiently. In this blog, you’ll understand: Partitioning splits data based on column values into separate folders, while bucketing divides data into fixed files based on hashing. What is Partitioning in Hive? Partitioning divides data into folders based on column values. In simple terms: Data is stored in separate directories based on partition column. Partitioning Example Data stored like: sales/year=2026/month=03/day=28/ Each partition stores specific data. Why Partitioning is Used Example: Query only one day instead of full table. When to Use Partitioning Use partitioning when: What is Bucketing in Hive? Bucketing divides data into fixed number of files. In simple terms: Data is split into equal parts using hashing. Bucketing Example Table divided into 4 buckets: Why Bucketing is Used When to Use Bucketing Use bucketing when: Partitioning vs Bucketing Difference Partitioning: Bucketing: Partitioning vs Bucketing Partitioning: Bucketing: How They Work Together In real projects, both are used. Flow: This improves performance. Real-World Example E-commerce data: Common Mistakes
