

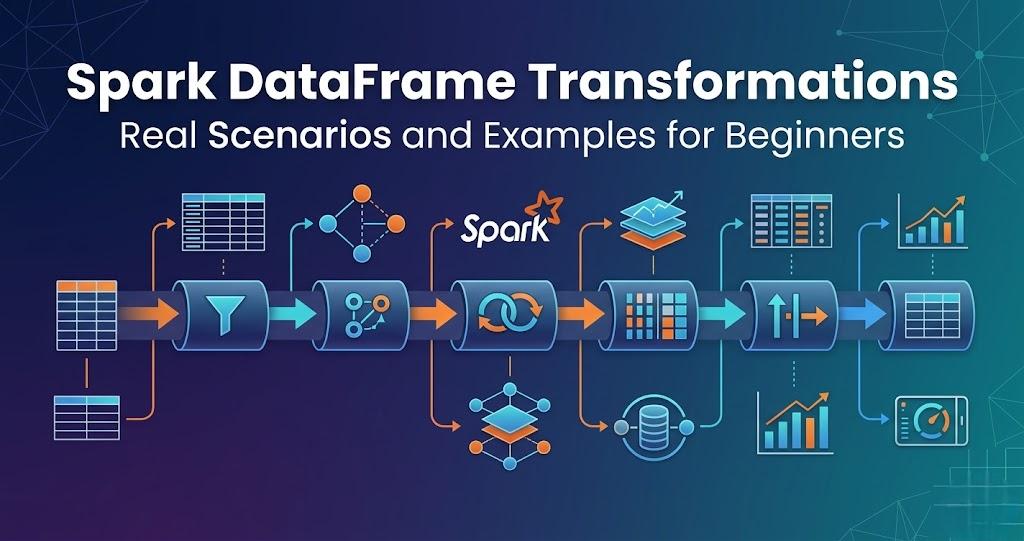
Introduction Trying to learn Spark DataFrame transformations but getting confused where and how to use them? You’re not alone. Most people: But when asked how transformations are used in real data pipelines, they get stuck. Because knowing functions is not equal to knowing when to use them. In this blog, you’ll understand: What are Spark DataFrame Transformations? Transformations are operations applied to data. Examples: In simple terms: Transformations modify data. Important Concept Transformations do not execute immediately. They are executed only when an action is called. This is called lazy execution. Scenario 1: Filtering Data (filter) Use case: Remove invalid records. Example: Flow: Read data → Filter → Clean data Scenario 2: Selecting Columns (select) Use case: Pick only required columns. Example: Flow: Read → Select → Reduce data Scenario 3: Aggregation (groupBy) Use case: Summarize data. Example: Flow: Read → groupBy → Aggregate Scenario 4: Joining Data (join) Use case: Combine multiple datasets. Example: Flow: Read → Join → Combined dataset Scenario 5: Removing Duplicates Use case: Clean duplicate data. Example: Flow: Read → Remove duplicates → Clean data Scenario 6: Adding New Columns Use case: Create derived columns. Example: Flow: Read → Add column → Enhanced data Scenario 7: Sorting Data Use case: Arrange data. Example: Flow: Read → Sort → Ordered data Scenario 8: Handling Null Values Use case: Fix missing data. Example: Flow: Read → Handle nulls → Clean data How Transformations Fit in Data Pipeline Typical flow: Transformations are core of processing. Real-World Example E-commerce pipeline: Common Mistakes
Batch vs Real-Time Processing – What’s the Difference and When to Use?
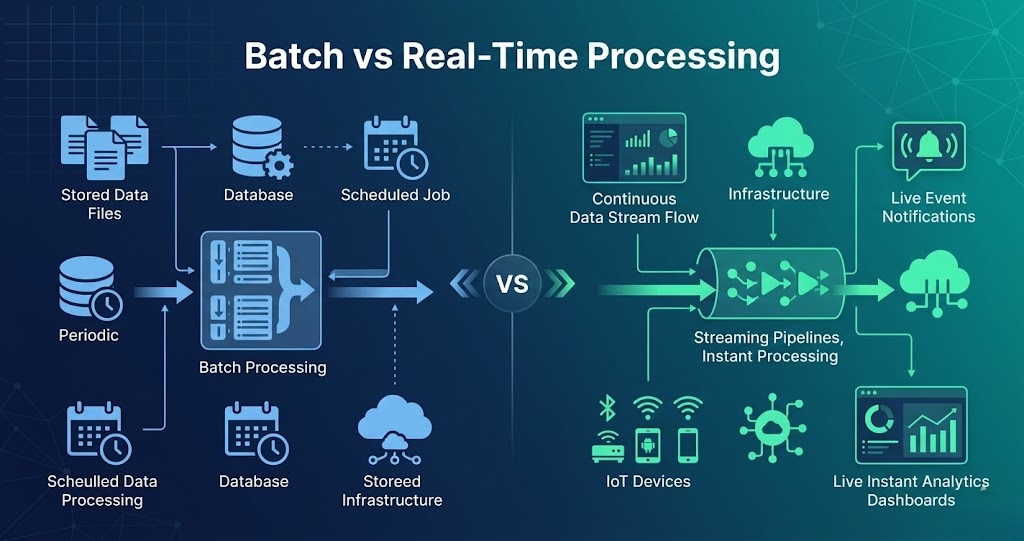
Batch vs Real-Time Processing – Difference, Examples, and Use Cases Introduction Trying to understand batch vs real-time processing but getting confused? You’re not alone. Most people: But when asked the difference in real systems, they get stuck. Because knowing definitions is not equal to understanding how data is processed. In this blog, you’ll understand: Batch vs Real-Time Processing in One Line Batch processing handles large volumes of data at scheduled intervals, while real-time processing handles data instantly as it arrives. What is Batch Processing? Batch processing means processing data in bulk. Data is collected over time and processed together. In simple terms: Data is processed after some delay. Batch Processing Flow Example: Daily sales report processed at midnight. What is Real-Time Processing? Real-time processing means processing data instantly. Data is processed as soon as it arrives. In simple terms: Data is processed immediately. Real-Time Processing Flow Example: Payment transaction processing. Batch vs Real-Time Processing Difference Batch Processing: Real-Time Processing: Batch vs Real-Time Processing Batch: Real-Time: Batch vs Real-Time Example Batch Example: Real-Time Example: When to Use Batch Processing Use batch when: When to Use Real-Time Processing Use real-time when: Why Both are Used Together In real projects, both are used. Flow: Real-World Example E-commerce pipeline: Real-Time: Batch: Common Mistakes
Top 10 Tools Every Data Engineer Must Know (Complete Guide 2026)
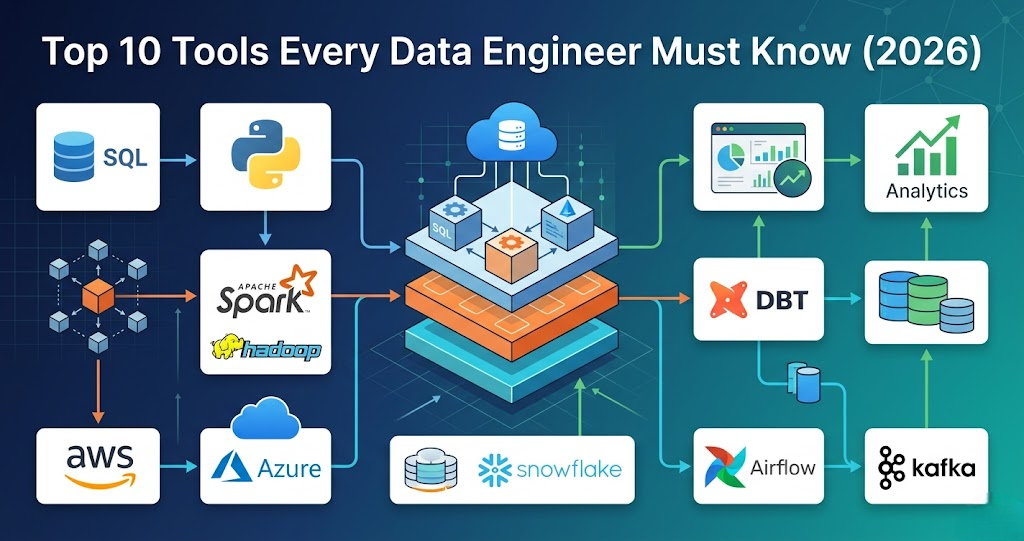
Introduction Trying to learn Data Engineering but confused about which tools are actually important? You’re not alone. Most people: But when asked what tools are used in real data engineering projects, they get stuck. Because knowing many tools is not equal to knowing the right tools. In this blog, you’ll understand: Data engineering tools are used to collect, store, process, and analyze data in pipelines. 1. SQL (Most Important Tool) SQL is used for: In real projects: SQL is used in almost every step of the pipeline. 2. Python (Core Programming Language) Python is used for: Used with: 3. Apache Spark (Processing Engine) Spark is used for: In real projects: Spark handles big data processing. 4. Apache Hadoop (Storage + Processing) Hadoop provides: Used for: 5. AWS (Cloud Platform) AWS is widely used in data engineering. Services include: Used to build full pipelines. 6. Azure (Cloud Platform) Azure provides: Used for enterprise data pipelines. 7. Databricks (Spark Platform) Databricks is used for: Makes Spark easier to use. 8. Apache Airflow (Orchestration) Airflow is used for: Controls pipeline execution. 9. Kafka (Streaming Platform) Kafka is used for: Used when data comes continuously. 10. Data Warehouse (Analytics Layer) Examples: Used for: How These Tools Work Together In real projects: Real-World Example E-commerce pipeline: Common Mistakes
AWS Glue Explained with Real Example (Complete Guide for Data Engineers 2026)
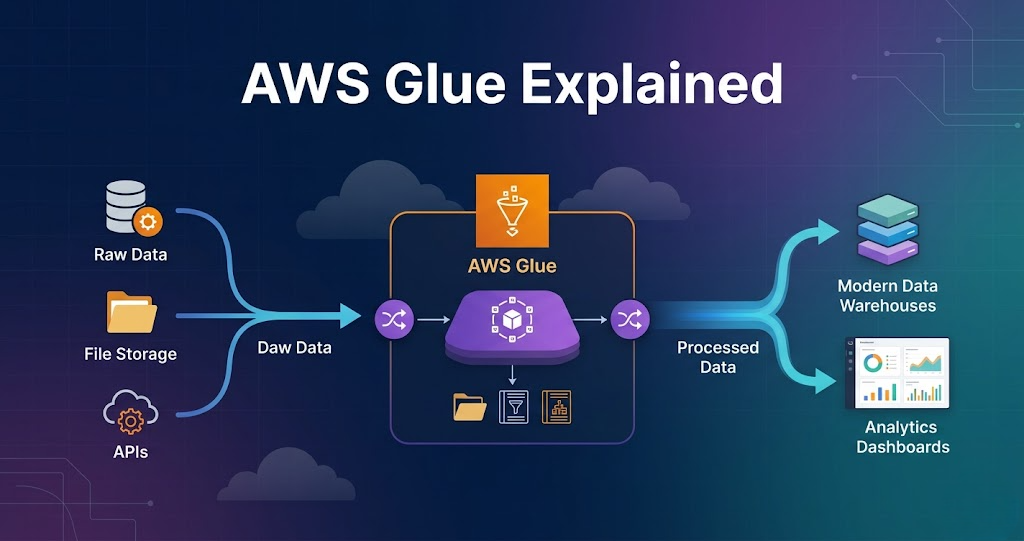
AWS Glue Explained with Real Example – Complete Guide for Data Engineers Introduction Trying to learn AWS Glue but feeling confused how it is actually used in real data engineering projects? You’re not alone. Most people: But when asked how AWS Glue fits into a real data pipeline, they get stuck. Because knowing AWS Glue features is not equal to knowing how it is used in real projects. In this blog, you’ll understand: What is AWS Glue? AWS Glue is a serverless data processing service used for ETL (Extract, Transform, Load). AWS Glue is used to process and transform data. AWS Glue in Data Engineering In real projects, AWS Glue is used for: AWS Glue is the core processing layer in AWS pipelines. Step 1: Data Source (Where Data Starts) Data comes from: Example: Data is stored in Amazon S3 raw layer. Step 2: Glue Crawlers (Schema Detection) Glue crawler scans data. It: Stored in: This helps query data easily. Step 3: Glue Jobs (Core Processing) Glue jobs perform transformations. Using: Tasks include: This is where real processing happens. Step 4: Transformations Common transformations: Flow: Read → Transform → Write Step 5: Data Output Processed data is written to: Data is stored in: Step 6: Integration with Other Services AWS Glue works with: Flow: Lambda → Glue → S3 → Redshift Step 7: Scheduling and Automation Glue jobs can be: Ensures pipelines run automatically. Step 8: Monitoring and Logging Glue provides: Used for debugging. Real Example (End-to-End Pipeline) E-commerce pipeline: Why AWS Glue is Important Without Glue, processing becomes complex. Common Mistakes
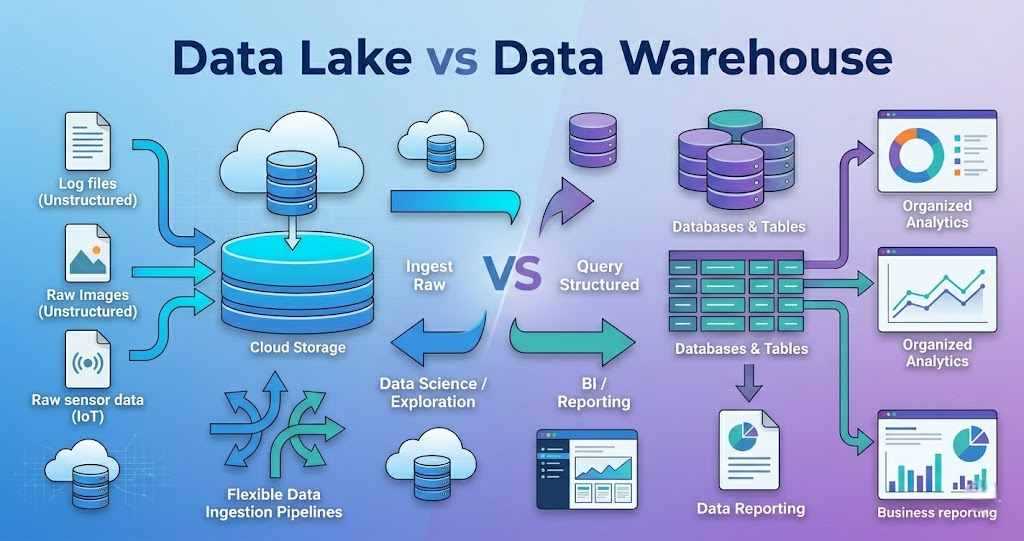
Data Lake vs Data Warehouse in Data Engineering – Key Differences and Use Cases
Introduction Trying to understand Data Lake vs Data Warehouse but getting confused? You’re not alone. Most people: But when asked the difference in real projects, they get stuck. Because knowing definitions is not equal to understanding how data is stored and used. In this blog, you’ll understand: A Data Lake stores raw data, while a Data Warehouse stores processed and structured data for analytics. What is a Data Lake? A Data Lake is a storage system that stores data in raw format. It stores: In simple terms: Data Lake stores everything as it is. Data Lake Flow Example: API → S3 → Processing What is a Data Warehouse? A Data Warehouse is used to store processed and structured data. It stores: In simple terms: Data Warehouse stores data for reporting and analytics. Data Warehouse Flow Example: API → Processing → Redshift Data Lake vs Data Warehouse Difference Data Lake: Data Warehouse: Data Lake vs Data Warehouse Data Lake: Data Warehouse: Data Lake vs Data Warehouse Example Data Lake Example: Data Warehouse Example: When to Use Data Lake Use Data Lake when: When to Use Data Warehouse Use Data Warehouse when: Why Both are Used Together In real projects, both are used. Flow: Real-World Example Retail pipeline: Common Mistakes

Databricks Complete Guide for Beginners (Step-by-Step 2026)
Introduction Trying to learn Databricks but feeling confused how it is actually used in real data engineering projects? You’re not alone. Most people: But when asked how Databricks fits into a real data pipeline, they get stuck. Because knowing Databricks features is not equal to knowing how it is used in real projects. In this blog, you’ll understand: What is Databricks? Databricks is a cloud-based platform built on Apache Spark. It is used for: In simple terms: Databricks is a platform that runs Spark and makes it easier to use. Step 0: Setup (Before Everything) Before using Databricks, setup is required. In real projects: Ensures: Step 1: Data Storage (Where Data Lives) Databricks does not store data permanently. Data is stored in: Databricks reads and writes data from these systems. Step 2: Clusters (Execution Engine) Cluster is the core of Databricks. Cluster is a group of machines. It is used to: Without cluster, nothing runs. Step 3: Notebooks (Development Layer) Notebooks are used to write code. Supported languages: Used for: Step 4: Data Processing (Core Layer) This is where real work happens. Using Spark: Flow: Read → Transform → Write Step 5: Job Execution Databricks allows scheduling jobs. You can: Used for production pipelines. Step 6: Integration with Pipelines Databricks works with: Flow: Orchestration tool → Databricks → Process data Step 7: Monitoring and Debugging Databricks provides: Used for debugging issues. Step 8: Security and Access Control Security is managed using: Ensures secure data pipelines. Step 9: Data Pipeline Flow Complete pipeline: Real-World Example E-commerce pipeline: Why Databricks is Important Without Databricks, Spark becomes harder to manage. Common Mistakes
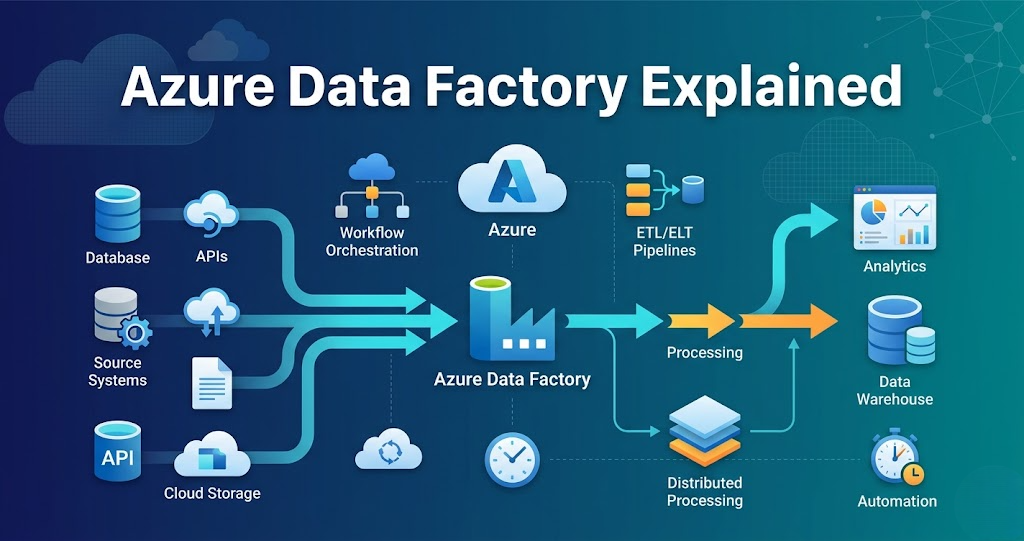
Azure Data Factory Explained for Data Engineers (Real Use Cases 2026)
Azure Data Factory Explained – Complete Guide for Data Engineers 2026 Introduction Trying to learn Azure Data Factory but feeling confused how it is actually used in real data engineering projects? You’re not alone. Most people: But when asked to build an end-to-end data pipeline, they get stuck. Because knowing Azure Data Factory features is not equal to knowing how to connect them in real projects. In this blog, you’ll understand: What is Azure Data Factory? Azure Data Factory is a cloud service used for: Using services like: In simple terms: You use Azure Data Factory to move data and control the pipeline. Step 0: Setup (Foundation Before Everything) Before building pipelines, setup is required. In real projects, everything is created using automation. Tools used: Used for: Ensures: Step 1: Data Storage (Data Lake Foundation) Every pipeline starts with storage. Azure Data Lake is used to store: Typical structure: Without proper storage design, pipelines become difficult to manage. Step 2: Data Ingestion (How Data Enters) Azure Data Factory is mainly used for ingestion. Data comes from: Using: Example: Database → Data Lake using Data Factory Step 3: Pipelines (Core Control Layer) Pipeline is the main component. Pipeline is a collection of activities. It controls: Without pipelines, there is no workflow. Step 4: Activities (Execution Units) Activities are tasks inside pipelines. Examples: Each activity performs a specific operation. Step 5: Triggering Processing (Integration with Databricks) Azure Data Factory does not process heavy data. It triggers: Flow: Data Factory → Databricks → Process data This is where real data transformation happens. Step 6: Orchestration (Pipeline Automation) Pipelines are automated. Using: Ensures: Step 7: Monitoring and Logging Production pipelines must be monitored. Using: Tracks: Step 8: Security and Access Control Security is critical. Used for: Ensures: Step 9: Data Quality and Validation Data must be validated. Checks include: Ensures reliable pipelines. Step 10: CI/CD (Deployment Automation) Pipelines are deployed using automation. Flow: Removes manual effort. Step 11: Execution Layer Processing happens in: Data Factory only controls execution. Step 12: End-to-End Azure Data Pipeline Putting everything together:
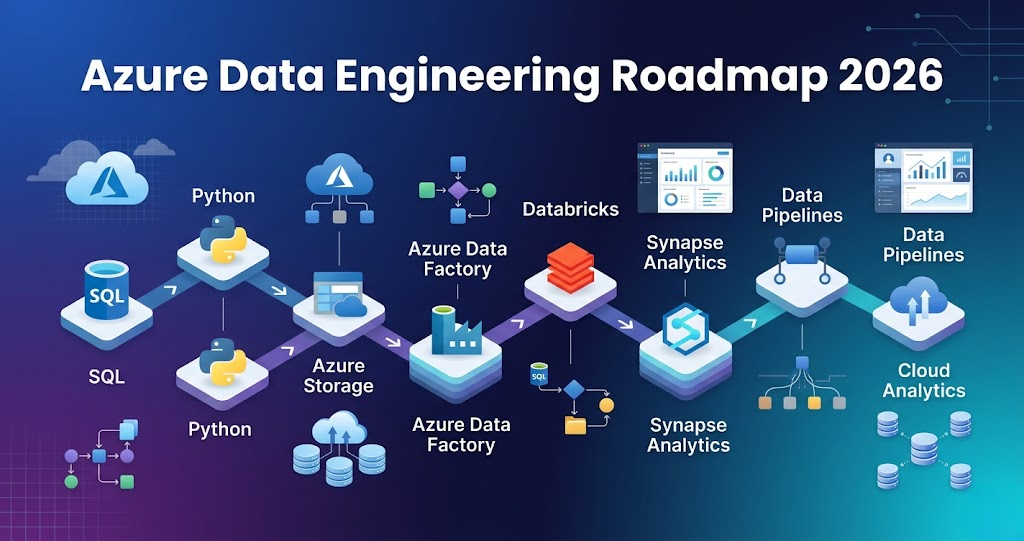
Azure Data Engineering Roadmap 2026 – Step-by-Step Guide to Become a Data Engineer
Azure Data Engineering Roadmap 2026 – Step-by-Step Guide for Beginners Introduction Trying to learn Azure Data Engineering but feeling lost? You’re not alone. Most people: But when asked to build a complete data pipeline, they get stuck. Because knowing tools is not equal to knowing how to connect them. In this blog, you’ll get a clear, step-by-step Azure Data Engineering roadmap that shows: What is Azure Data Engineering? Azure Data Engineering is the process of: Using Azure services like: In simple terms: You build data pipelines that move and transform data on Azure. Step 0: Foundation (Before Azure) Before learning Azure tools, you must learn basics. Learn: These are core skills required for any data engineer. Step 1: Data Storage (Azure Data Lake) Every pipeline starts with storage. Azure Data Lake Storage is used to store: Typical structure: Without proper storage design, pipelines become difficult to manage. Step 2: Data Ingestion (How Data Enters) Data comes from multiple sources: Azure Data Factory is used for ingestion. It supports: Azure Data Factory helps move data from source to storage. Step 3: Data Processing (Core Layer) This is where data is transformed. Tools used: Typical work: This is where raw data becomes useful. Step 4: Data Warehousing (Analytics Layer) After processing, data is stored for analytics. Azure Synapse Analytics is used for: Proper table design improves performance. Step 5: Orchestration (Pipeline Automation) Pipelines are not run manually. Tools used: They control: Step 6: Monitoring and Logging Production pipelines must be monitored. Tools: Used for: Step 7: Security and Access Control Security is very important. Used for: Azure uses: Step 8: Core Skills (Must Have) To succeed in Azure Data Engineering: SQL Python Spark These are mandatory skills. Step 9: Data Quality and Testing Data must be validated before use. Includes: Ensures reliable pipelines. Step 10: CI/CD and Deployment Modern pipelines use automation. Flow: Step 11: Execution Layer Data processing runs on: This is where large-scale data is processed. Step 12: End-to-End Azure Data Pipeline Complete flow:
Spark vs Hadoop vs Databricks (Clear Comparison for Beginners 2026)
Introduction Trying to understand Spark vs Hadoop vs Databricks but getting confused? You’re not alone. Most people: But when asked how they are different and where each one is used, they get stuck. Because knowing tools is not equal to understanding how they fit in real data pipelines. In this blog, you’ll understand: Hadoop is used for storage and batch processing, Spark is used for fast data processing, and Databricks is a platform that makes Spark easy to use and manage. What is Hadoop? Hadoop is a big data framework used for storing and processing large datasets. It mainly includes: In simple terms: Hadoop stores and processes data in batches. What is Spark? Apache Spark is a fast data processing engine. It is used for: In simple terms: Spark processes data faster than Hadoop. What is Databricks? Databricks is a cloud platform built on top of Apache Spark. It provides: In simple terms: Databricks makes Spark easier to use. Spark vs Hadoop vs Databricks Difference Hadoop: Spark: Databricks: Spark vs Hadoop vs Databricks Comparison Hadoop: Spark: Databricks: When to Use Hadoop Use Hadoop when: When to Use Spark Use Spark when: When to Use Databricks Use Databricks when: Real-World Example Pipeline: This is how they work together. Why Spark Replaced Hadoop MapReduce So most modern systems use Spark instead of MapReduce. Common Mistakes
Apache Spark Basics for Beginners (Complete Guide 2026)
Introduction Trying to learn Apache Spark but feeling confused where to start? You’re not alone. Most people: But when asked how Spark works in a real data pipeline, they get stuck. Because knowing Spark concepts is not equal to understanding how Spark processes data. In this blog, you’ll understand: What is Apache Spark? Apache Spark is a distributed data processing engine used to process large amounts of data. In simple terms: Spark is used to process big data quickly. Apache Spark processes large data across multiple machines in parallel. How Spark is Used in Data Engineering In real projects, Spark is used for: Spark is the core processing engine in data pipelines. Step 1: How Data is Processed in Spark Spark does not process data in one machine. It splits data into smaller parts and processes them in parallel. Flow: This is why Spark is fast. Step 2: Spark Architecture (Simple View) Spark has two main parts: Driver: Executors: Flow: Driver → Executors → Result Step 3: Transformations in Spark Transformations are operations applied to data. Examples: Important: Transformations do not execute immediately. They are stored as a plan. Step 4: Actions in Spark Actions trigger execution. Examples: Once an action is called, Spark runs the job. Step 5: Lazy Execution (Important Concept) Spark does not execute transformations immediately. It waits until an action is called. Then it runs everything together. This is called lazy execution. Step 6: Narrow vs Wide Transformations Narrow transformations: Wide transformations: Example: filter → narrowgroupBy → wide Step 7: Spark in Real Data Pipeline Typical flow: Spark sits in the processing layer. Real-World Example E-commerce pipeline: Key Features of Apache Spark Fast Processing Processes data in parallel Scalability Handles large datasets Fault Tolerance Handles failures automatically Flexibility Supports multiple languages Common Mistakes These slow down Spark jobs. Why Spark is Important in Data Engineering
