

Introduction
Trying to learn Data Engineering but confused about which tools are actually important?
You’re not alone.
Most people:
- Learn random tools
- Follow multiple courses
- Get overwhelmed
But when asked what tools are used in real data engineering projects, they get stuck.
Because knowing many tools is not equal to knowing the right tools.
In this blog, you’ll understand:
- Top 10 tools every data engineer must know
- How these tools are used in real projects
- Where each tool fits in a data pipeline
Data engineering tools are used to collect, store, process, and analyze data in pipelines.
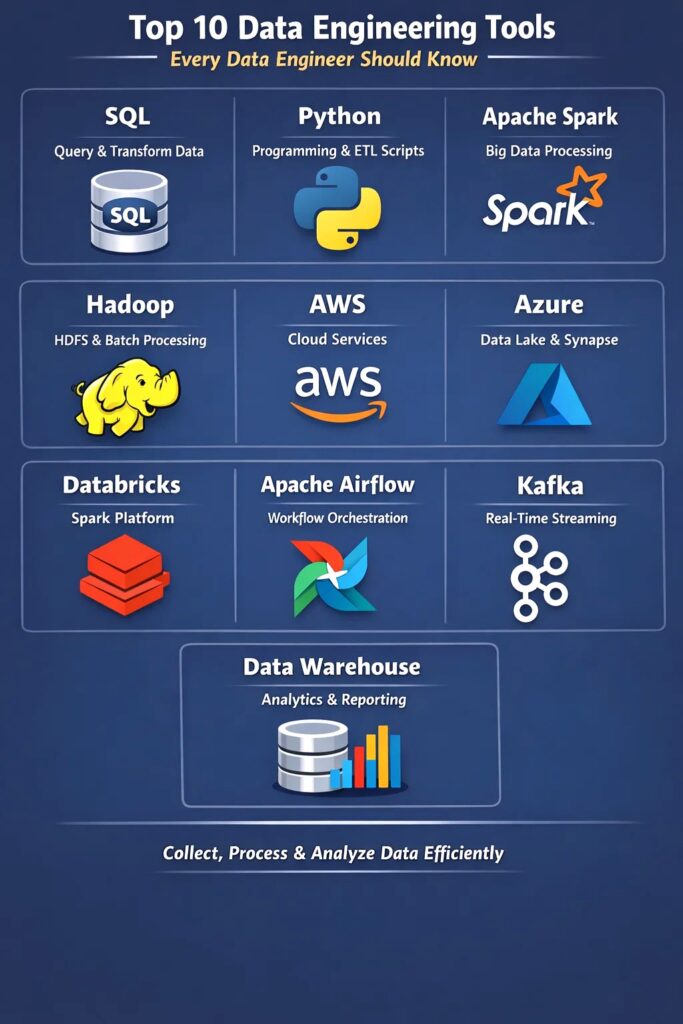
1. SQL (Most Important Tool)
SQL is used for:
- Querying data
- Data validation
- Transformations
In real projects:
SQL is used in almost every step of the pipeline.
2. Python (Core Programming Language)
Python is used for:
- Automation
- Data processing
- Writing ETL pipelines
Used with:
- AWS Glue
- APIs
- Data pipelines
3. Apache Spark (Processing Engine)
Spark is used for:
- Processing large datasets
- ETL pipelines
- Data transformations
In real projects:
Spark handles big data processing.
4. Apache Hadoop (Storage + Processing)
Hadoop provides:
- HDFS (storage)
- Batch processing
Used for:
- Large-scale storage
- Distributed systems
5. AWS (Cloud Platform)
AWS is widely used in data engineering.
Services include:
- S3 (storage)
- Lambda (triggers)
- Glue (processing)
- Redshift (analytics)
Used to build full pipelines.
6. Azure (Cloud Platform)
Azure provides:
- Data Lake
- Data Factory
- Databricks
- Synapse
Used for enterprise data pipelines.
7. Databricks (Spark Platform)
Databricks is used for:
- Running Spark jobs
- Data transformation
- Analytics
Makes Spark easier to use.
8. Apache Airflow (Orchestration)
Airflow is used for:
- Scheduling pipelines
- Managing workflows
Controls pipeline execution.
9. Kafka (Streaming Platform)
Kafka is used for:
- Real-time data processing
- Streaming pipelines
Used when data comes continuously.
10. Data Warehouse (Analytics Layer)
Examples:
- Redshift
- Snowflake
- BigQuery
Used for:
- Reporting
- Dashboards
- Analytics
How These Tools Work Together
In real projects:
- Data comes from source
- Stored in S3 or Data Lake
- Processed using Spark or Glue
- Orchestrated using Airflow
- Loaded into Data Warehouse
- Used for analytics
Real-World Example
E-commerce pipeline:
- Orders data generated
- Stored in S3
- Processed using Spark
- Orchestrated using Airflow
- Loaded into Redshift
- Dashboard shows results
Common Mistakes
- Learning too many tools at once
- Not understanding pipeline flow
- Focusing only on theory
