

Introduction
Trying to understand Spark vs Hadoop vs Databricks but getting confused?
You’re not alone.
Most people:
- Learn Hadoop separately
- Learn Spark separately
- Hear about Databricks in projects
But when asked how they are different and where each one is used, they get stuck.
Because knowing tools is not equal to understanding how they fit in real data pipelines.
In this blog, you’ll understand:
- What Hadoop is
- What Spark is
- What Databricks is
- Key differences
- When to use each
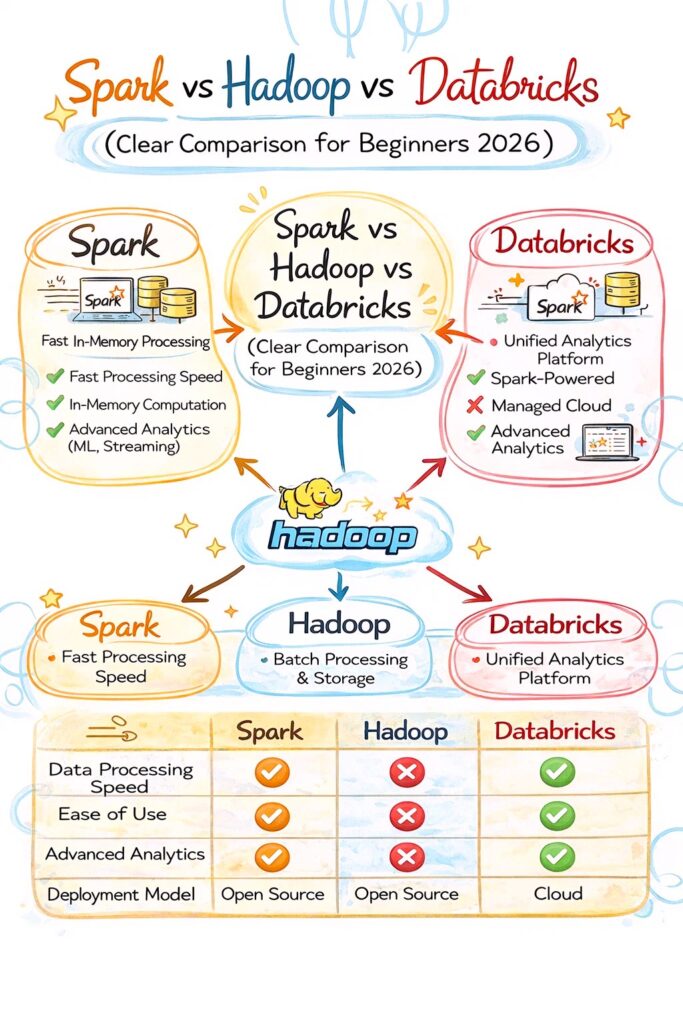
Hadoop is used for storage and batch processing, Spark is used for fast data processing, and Databricks is a platform that makes Spark easy to use and manage.
What is Hadoop?
Hadoop is a big data framework used for storing and processing large datasets.
It mainly includes:
- HDFS (storage)
- MapReduce (processing)
In simple terms:
Hadoop stores and processes data in batches.
What is Spark?
Apache Spark is a fast data processing engine.
It is used for:
- Data transformation
- ETL pipelines
- Real-time processing
In simple terms:
Spark processes data faster than Hadoop.
What is Databricks?
Databricks is a cloud platform built on top of Apache Spark.
It provides:
- Managed Spark environment
- Notebooks
- Easy cluster management
In simple terms:
Databricks makes Spark easier to use.
Spark vs Hadoop vs Databricks Difference
Hadoop:
- Batch processing
- Disk-based
- Slower
Spark:
- Fast processing
- In-memory processing
- Supports batch and real-time
Databricks:
- Managed Spark platform
- Easy to use
- Cloud-based
Spark vs Hadoop vs Databricks Comparison
Hadoop:
- Storage + processing
- Uses HDFS
- Uses MapReduce
Spark:
- Processing engine
- Works with multiple storage systems
- Faster than Hadoop
Databricks:
- Platform for Spark
- Provides UI and tools
- Simplifies development
When to Use Hadoop
Use Hadoop when:
- You need distributed storage (HDFS)
- Working with large batch data
- Cost is a concern
When to Use Spark
Use Spark when:
- You need fast processing
- Working with large datasets
- Building ETL pipelines
When to Use Databricks
Use Databricks when:
- You want managed Spark
- Working in cloud environments
- Need faster development
Real-World Example
Pipeline:
- Data stored in HDFS or S3
- Spark processes data
- Databricks used to run Spark jobs
This is how they work together.
Why Spark Replaced Hadoop MapReduce
- Faster processing
- In-memory execution
- Easier development
So most modern systems use Spark instead of MapReduce.
Common Mistakes
- Thinking Hadoop and Spark are same
- Assuming Databricks is a tool instead of a platform
- Not understanding their roles
