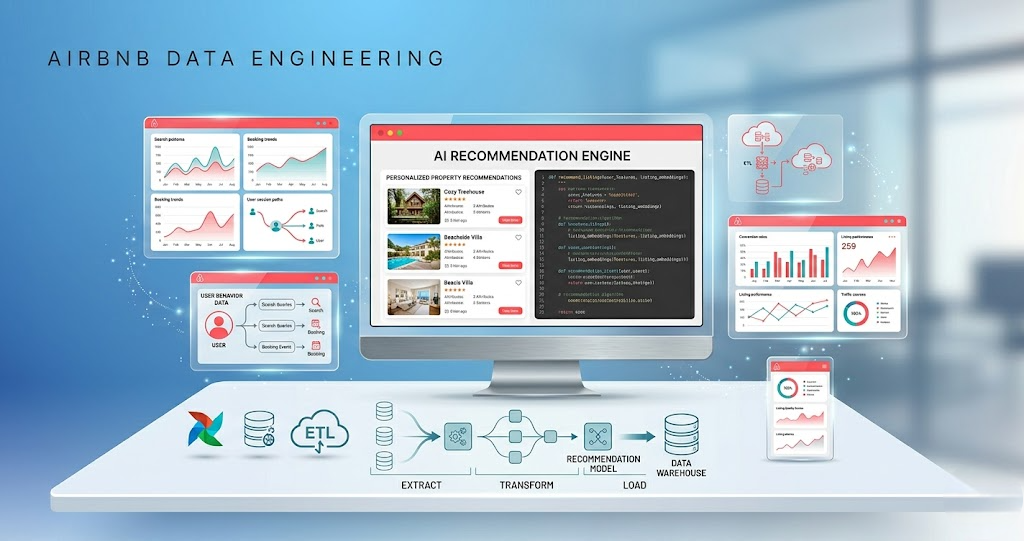

Introduction
Trying to understand SCD Type 2 in Spark but getting confused?
You’re not alone.
Most people:
- Learn SCD types in theory
- Memorize definitions
- Practice small examples
But when asked how SCD Type 2 is implemented in real data pipelines, they get stuck.
Because knowing theory is not equal to knowing how data actually changes in production systems.
In this blog, you’ll understand:
- What SCD Type 2 is
- Why it is used
- How it works in Spark
- Step-by-step real pipeline flow
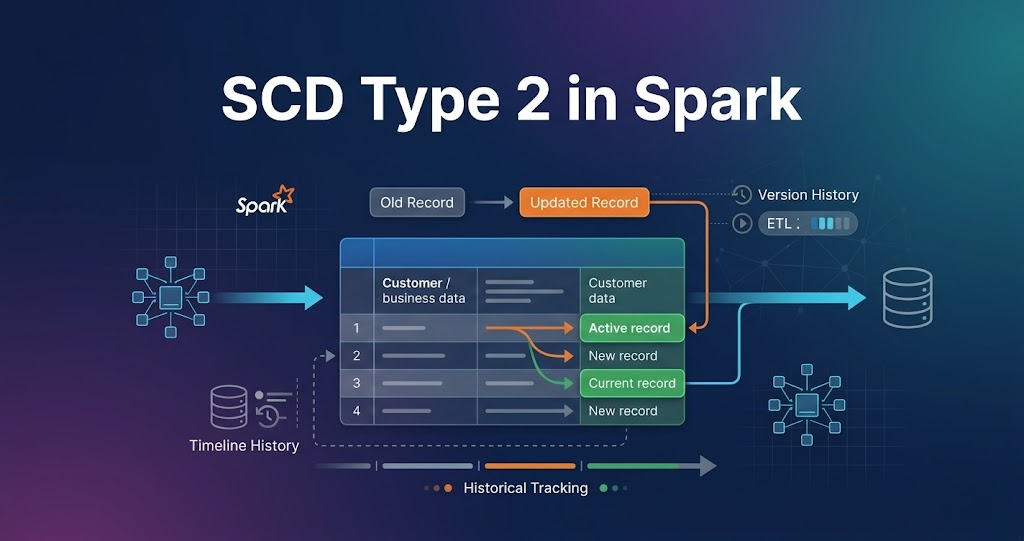
SCD Type 2 in Spark is used to track historical data changes by inserting new records and marking old records as inactive instead of updating them.
What is Slowly Changing Dimension (SCD)?
Slowly Changing Dimension is used to track changes in data over time.
Example:
When a customer changes city, instead of updating the existing record, a new record is created and history is preserved.
What is SCD Type 2?
SCD Type 2 stores full history of changes.
In simple terms:
Whenever data changes, a new record is created, and the previous record is marked as inactive.
Why SCD Type 2 is Important
- Tracks historical data
- Maintains audit history
- Supports time-based reporting
Without SCD Type 2, old data is lost.
Key Columns in SCD Type 2
Typical columns used:
- id (business key)
- start_date
- end_date
- is_active
These columns help track when data was valid.
Real Scenario
Customer changes city from Delhi to Mumbai.
Instead of updating the old record:
- Old record is marked inactive
- New record is inserted
This keeps complete history.
Step-by-Step SCD Type 2 in Spark (Real Flow)
Step 1: Read Source Data
New data comes from source systems.
Step 2: Read Existing Data
Existing data contains historical records.
Step 3: Filter Active Records
Only active records are considered for comparison.
Step 4: Identify Changes
New data is compared with existing active data to find changes.
Step 5: Expire Old Records
Old records are updated:
- end_date is set
- is_active is set to false
Step 6: Insert New Records
New records are inserted with:
- Updated values
- start_date set
- end_date as null
- is_active as true
Step 7: Keep Unchanged Records
Records with no changes are kept as is.
Step 8: Merge All Records
All records are combined:
- unchanged records
- expired records
- new records
Step 9: Write Back Data
Final dataset is written back to storage.
SCD Type 2 Flow in Spark
- Read new data
- Read existing data
- Filter active records
- Identify changes
- Expire old records
- Insert new records
- Combine all records
- Write back
Real-World Pipeline
- Data stored in S3
- Spark reads data
- Applies SCD Type 2 logic
- Writes updated data
- Used for reporting
SCD Type 2 in Spark is widely used in data engineering pipelines to maintain historical data.
Common Mistakes
- Overwriting old data
- Not filtering active records
- Missing start and end dates
- Incorrect comparison logic
These issues break SCD Type 2 implementation